Kyle Simpson
You Don't Know JS

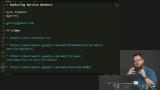
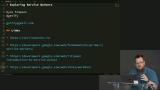
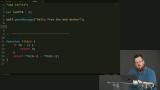
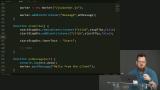
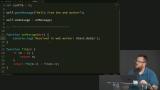
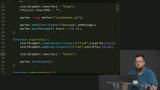
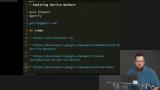
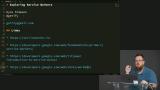
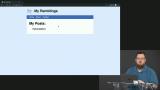
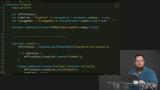
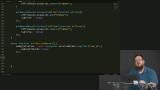
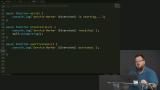
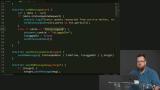
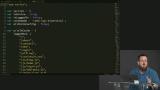
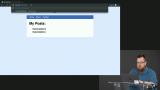
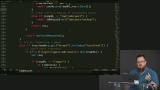
You’ve likely heard the term “Progressive Web Apps” (PWAs). Sure, it's a buzz word that's a bit overloaded, but it has some great motivations behind it. PWAs represent the dream of web apps getting all the same capabilities, and performance, of native apps. At the core of making this happen is the new Service Workers API. Service Workers give web apps new capabilities to be able to go beyond the browser tab and enable features like smart offline caching and PWA features like push notifications!
This course and others like it are available as part of our Frontend Masters video subscription.