

This Part 1 (of a 2-part series) is a practical, hands-on, applicable approach to database indexes. We’ll cover what B Trees are with a focus on deeply understanding, and internalizing how they store data on disk, and how your database uses them to speed up queries.
This will set us up nicely for part 2, where we’ll explore some interesting, counterintuitive ways to press indexes into service to achieve great querying performance over large amounts of data.
Article Series
There are other types of database indexes beside B Tree, but B Tree indexes are the most common, which is why they’ll be the exclusive focus of this post.
Everything in these posts will use Postgres, but everything is directly applicable to other relational databases (like MySQL). All the queries I’ll be running are against a simple books database which I scaffolded, and had Cursor populate with about 90 million records. The schema for the database, as well as the code to fill it are in this repo. If you’d like to follow along on your own: sql/db_create.sql has the DDL, and npx tsx insert-data/fill-database.ts will run the code to fill it.
We’ll be looking at some B Tree visualizations as we go. Those were put together with a web app I had Cursor help me build.
Editors’ note: Need to bone up on PostgreSQL all around? Our course Complete Intro to SQL & PostgreSQL from Brian Holt will be perfect for you.
Setting some baselines
Just for fun, let’s take a look at the first 10 rows in the books table. Don’t look too close, again, this was all algorithmically generated by AI. The special characters at the beginning were my crude way of forcing the (extremely repetitive) titles to spread out.

That’s the last time we’ll be looking at actual data. From here forward we’ll look at queries, the execution plans they generate, and we’ll talk about how indexes might, or might not be able to help. Rather than the psql terminal utility I’ll be running everything through DataGrip, which is an IDE for databases. The output is identical, except with nicely numbered lines which will make things easier to talk about as we go.
Let’s get started. Let’s see what the prior query looks like by putting explain analyze before it. This tells Postgres to execute the query, and return to us the execution plan it used, as well as its performance.
explain analyze
select * from books limit 10;
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)
We asked for 10 rows. The database did a sequential scan on our books table, but with a limit of 10. This couldn’t be a simpler query, and it returned in less than one twentieth of one millisecond. This is hardly surprising (or interesting). Postgres reached in and grabbed the first ten rows.
Let’s grab the first 10 books, but this time sorted alphabetically.

Catastrophically, this took 20 seconds. With 90 million rows in this table, Postgres now has to (kind of) sort the entire table, in order to know what the first 10 books are.
I say kind of since it doesn’t really have to sort the entire table; it just has to scan the entire table and keep track of the 10 rows with the lowest titles. That’s what the top-N heapsort is doing.
And it’s doing that in parallel. We can see two child workers getting spawned (in addition to the main worker already running our query) to each scan about a third of the table. Then the Gather Merge pulls from each worker until it has the top 10. In this case it only needed to pull the top 7 rows from each worker to get its 10; this is reflected in lines 3-9 of the execution plan.
Line 5 makes this especially clear
-> Sort (cost=2839564.34..2934237.14 rows=37869122 width=112) (actual time=20080.358..20080.359 rows=7 loops=3)
Notice the loops=3, and the rows=37 million. Each worker is scanning its share of the table, and keeping the top 7 it sees.
These 3 groups of 7 are then gathered and merged together in the Gather Merge on line 2
-> Gather Merge (cost=2840564.36..11677309.78 rows=75738244 width=112) (actual time=20093.790..20096.619 rows=10 loops=1)
Rather than just slapping an index in, and magically watching the time drop down, let’s take a quick detour and make sure we really understand how indexes work. Failing to do this can result in frustration when your database winds up not picking the index you want it to, for reasons that a good understanding could make clear.
Indexes
The best way to think about a database index is in terms of an index in a book. These list all the major terms in the book, as well as all the pages that the term appears on. Imagine you have a 1,000 page book on the American Civil War, and wanted to know what pages Philip Sheridan are mentioned on. It would be excruciatingly slow to just look through all 1,000 pages, searching for those words. But if there’s a 30 or so page index, your task is considerably simpler.
Before we go further, let’s look at a very basic index over a numeric id column

This is a B Tree, which is how (most) indexes in a database are stored.
Start at the very, very bottom. Those blue “leaf” nodes contain the actual data in your index. These are the actual id values. This is a direct analogue to a book’s index.
So what are the gold boxes above them? These help you find where the leaf node is, with the value you’re looking for.
Let’s go to the very top, to the root node of our B Tree. Each of these internal nodes will have N key values, and N+1 pointers. If the value you’re looking for is strictly less than the first value, go down that first, left-most arrow and continue your search. If the value you’re looking for is greater than or equal to that first key, but strictly less than the next key, take the second arrow. And so on. In real life the number of keys in each of these nodes will be determined by how many of them can fit into a single page on disk (and will usually be much more than 3).
So with this B Tree, if we want to find id = 33, we start at the root. The id 33 is not < 19, so we don’t take the first arrow. But 33 is >=19 and <37, so we take the middle arrow.
Now we repeat. The id 33 is not < 25, so we don’t take the left most path. The id 33 is not >= 25 AND < 31, so we don’t take the middle path. But 33 is greater than 31 (it better be, this is the last path remaining), so we take the right most path. And that takes us to the leaf node with our key value.
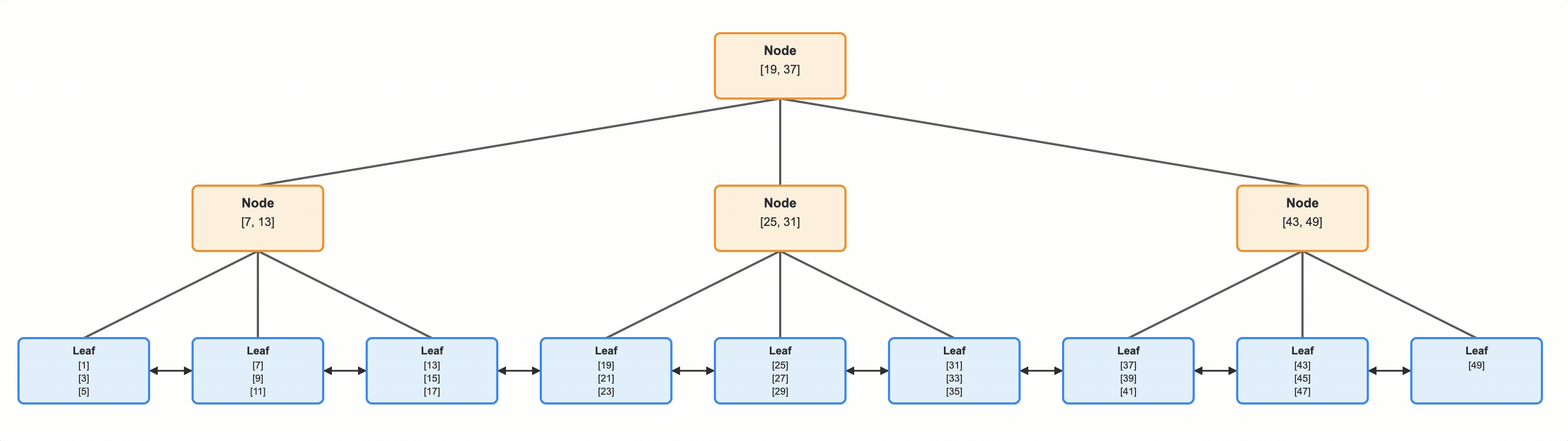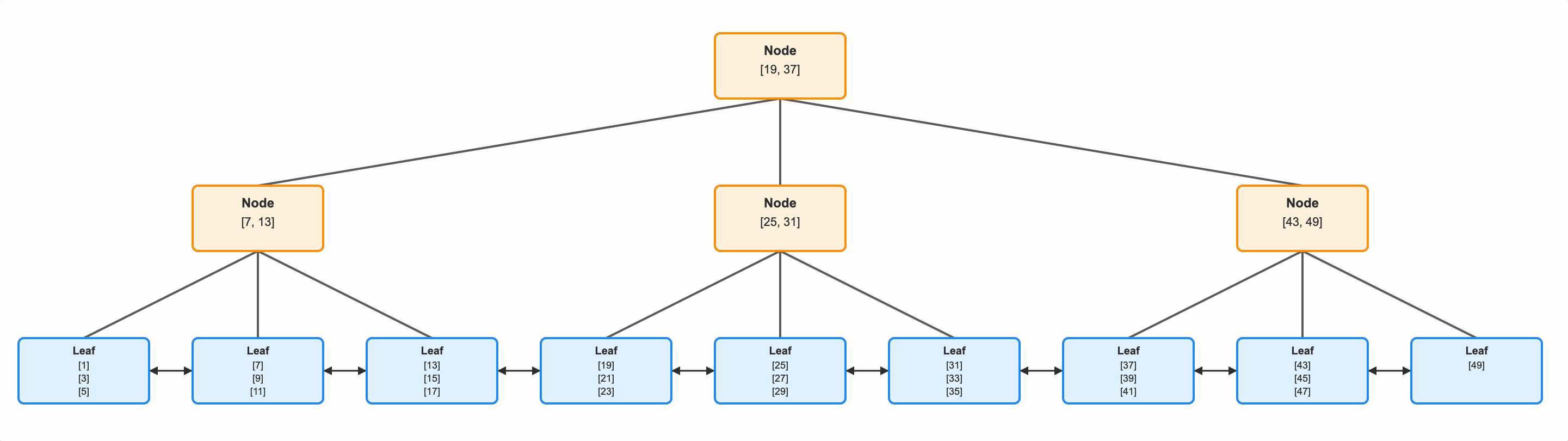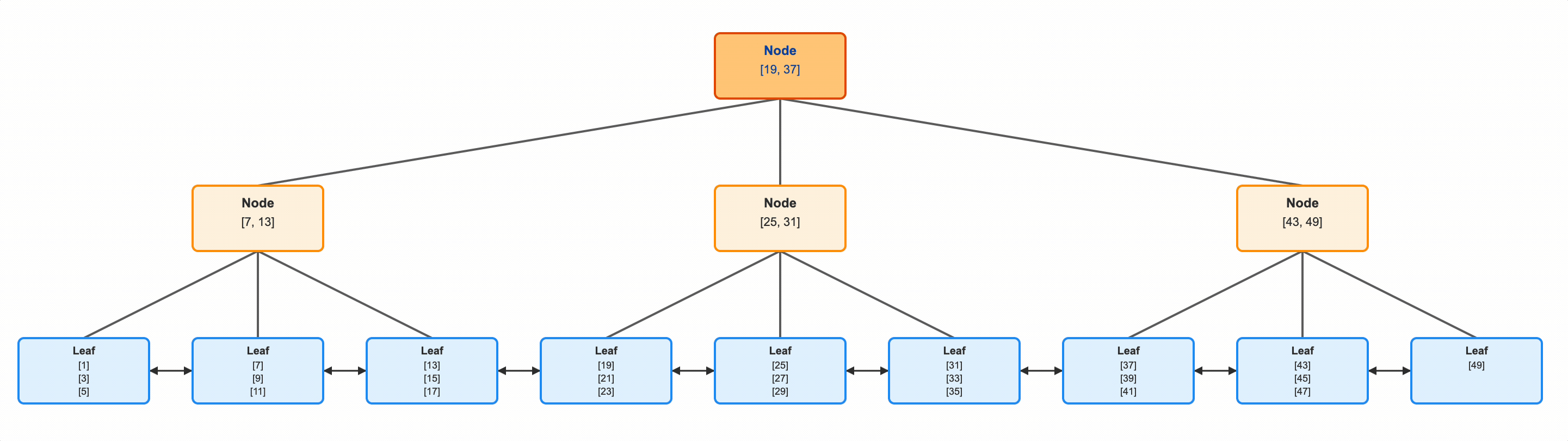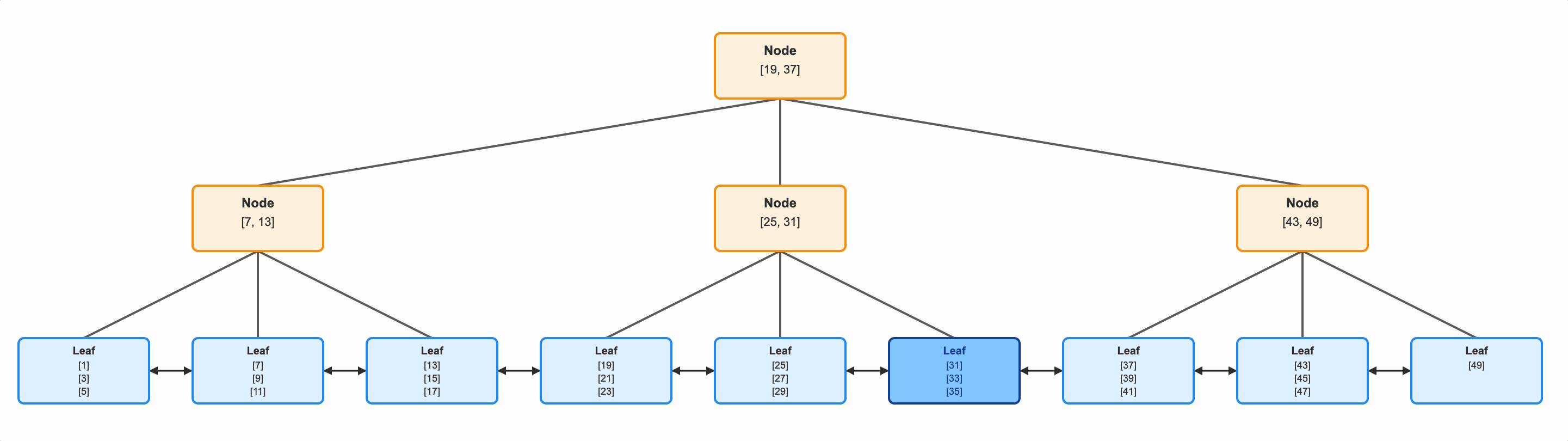
Notice also that these leaf nodes have pointers forward and backward. This allows us to not only find a specific key value, but also a range of values. If we wanted all ids > 33, we could do as we did, and just keep reading.

But — now what? What if we ran a query of SELECT * FROM books WHERE id = 33 – we’ve arrived at a leaf node in our index with … our key. How do we get all the data associated with that key? In other words the actual row in the database for that value?
The thing I’ve left off so far is that leaf nodes also contain pointers to the actual table where that value in question is.

Returning briefly to our analogy with a book’s index, those heap pointers correspond to the page number beside each index entry, telling you where to go in the book to see the actual content.
So the full story to find a single row in our database by an id value, via an index, would actually look more like this:

We’ll talk later about these heap reads, or lack thereof when we get into covering indexes and the Index Only Scan operation.
Bear with me a little longer. Before we look at what an index on title would look like, and create one in our database to run our query against, let’s take a slightly deeper look at B Trees. Internalizing how they work can be incredibly valuable.
B Trees run in O(LogN) time
You may have been taught a fun little math fact in school, that if you were to be given a penny on January 1st, then have your penny doubled on January 2nd, then have that new amount (2 cents) doubled on January 3rd, etc, you’d have about $10 million dollars before February. That’s the power of exponential operations. Anytime you’re repeatedly multiplying a value by some constant (which is all doubling is, for constant 2), it will become enormous, fast.
Now think of a more depressing, reverse scenario. If someone gave you $10 million on January 1st, but with the condition that your remaining money would be halved each day, you’d have a lowly cent remaining on Feb 1st. This is a logarithm; it’s the inverse of exponentiation. Rather than multiplying a value by some constant, we divide it by some constant. No matter how enormous, it will become small, fast.
This is exactly how B Trees work. In our example B Tree above, there were 9 leaf pages. Our internal nodes had up to 3 pointers. Notice that we were able to find out the exact leaf node we wanted by following only 2 of those gold nodes’ arrows (which is also the depth of the tree).
9 divided by 3 is 3
3 divided by 3 is 1
Or, more succinctly, Log39 = 2
Which reads as
Logarithm base 3 of 9 is 2
But these small values don’t really do this concept justice. Imagine if you had an index with whose leaves spanned 4 billion pages, and your index nodes had only 2 pointers, each (both of these assumptions are unrealistic). You’d still need only 32 page reads to find any specific value.
232 = ~4 billion
and also
Log2(~4 billion) = 32.
They’re literally inverse operations of each other.
How deep are real indexes?
Before we move on, let’s briefly look at how deep a real Postgres index is on a somewhat large amount of data. The books table with 90 million entries already has an index defined on the primary key id field, which is a 32 bit integer. Without going into gross detail about what all is stored on a B Tree node (N keys, N+1 offsets to other nodes, some metadata and headers, etc), ChatGPT estimates that Postgres can store between 400-500 key fields on an index on a 32 bit integer.
Let’s check that. There’s a Postgres extension for just this purpose.
CREATE EXTENSION IF NOT EXISTS pageinspect;Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)and then
SELECT * FROM bt_metap('books_pkey');
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)which produces
| magic | version | root | level | fastroot | fastlevel | last_cleanup_num_delpages | last_cleanup_num_tuples | allequalimage |
|---|---|---|---|---|---|---|---|---|
| 340322 | 4 | 116816 | 3 | 116816 | 3 | 0 | -1 | t |
Note the level 3, which is what our index’s depth is. That means it would take just 3 page reads to arrive at the correct B Tree leaf for any value (this excludes reading the root node itself, which is usually just stored in memory).
Checking the math, the Log450(90,000,000) comes out to … 2.998
Taking an index for a spin
Let’s run a quick query by id, with the primary key index that already exists, and then look at how we can create one on title, so we can re-run our query to find the first 10 books in order.
explain analyze
select *
from books
where id = 10000;
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)which produces the following

We’re running an index scan. No surprises there. The Index Cond
Index Cond: (id = 10000)is the condition Postgres uses to navigate the internal nodes; those were the gold nodes from the visualization before. In this case, it predictably looks for id = 10000
Re-visiting our titles sort
Let’s take a fresh look at this query.
select *
from books
order by title
limit 10;
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)This time let’s define an index, like so
CREATE INDEX idx_title ON books(title);
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)This index would look something like this (conceptually at least).

Now our query runs in less than a fifth of a millisecond.

Notice what’s missing from this execution plan, that was present on the previous query, when we looked for a single index value.
Did you spot it?
It’s the Index Cond. We’re not actually … looking for anything. We just want the first ten rows, sorted by title. The index stores all books, sorted by title. So the engine just hops right down to the start of the index, and simply reads the first ten rows from the leaf nodes (the blue nodes from the diagrams).
More fun with indexes
Let’s go deeper. Before we start, I’ll point out that values for the pages column was filled with random values from 100-700. So there are 600 possible values for pages, each randomly assigned.
Let’s look at a query to read the titles of books with the 3 maximum values for pages. And let’s pull a lot more results this time; we’ll limit it to one hundred thousand entries
explain analyze
select title, pages
from books
where pages > 697
limit 100000;
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)
As before, we see a parallel sequential scan. We read through the table, looking for the first 100,000 rows. Our condition matches very few results, so the database has to discard through over 6 million records before it finds the first 100,000 matching our condition
Rows Removed by Filter: 6627303
The whole operation took 833ms.
Let’s define an index on pages
CREATE INDEX idx_pages ON books(pages);
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)You might notice that the pages column is by no means unique; but that doesn’t effect anything: the leaf pages can easily contain duplicate entries.

Everything else works the same as it always has: the database can quickly jump down to a specific value. This allows us to query a particular value, or even grab a range of values sorted on the column we just looked up. For example, if we want all books with pages > 500, we just seek to that value, and start reading.
Let’s re-run that query from before
explain analyze
select title, pages
from books
where pages > 697
limit 100000;
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)
There’s a lot going on. Our index is being used, but not like before
-> Bitmap Index Scan on idx_pages (cost=0.00..4911.16 rows=451013 width=0) (actual time=38.057..38.057 rows=453891 loops=1)
Bitmap scan means that the database is scanning our table, and noting the heap locations with records matching our filter. It literally builds a bitmap of matching locations, hence the name. It then sorts those locations in order of disk access.
It then pulls those locations from the heap. This is the Bitmap Heap Scan on line 5
-> Parallel Bitmap Heap Scan on books (cost=5023.92..1441887.67 rows=187922 width=73) (actual time=41.383..1339.997 rows=33382 loops=3)
But remember, this is the heap, and it’s not ordered on pages, so those random locations may have other records not matching our filter. This is done in the Index Recheck on line 6
Recheck Cond: (pages > 697)
which removed 1,603,155 results.
Why is Postgres doing this, rather than just walking our index, and following the pointers to the heap, as before?
Postgres keeps track of statistics on which values are contained in its various columns. In this case, it knew that relatively few values would match on this filter, so it chose to use this index.
But that still doesn’t answer why it didn’t use a regular old index scan, following the various pointers to the heap. Here, Postgres decided that, even though the filter would exclude a large percentage of the table, it would need to read a lot of pages from the heap, and following all those random pointers from the index to the heap would be bad. Those pointers point in all manner of random directions, and Random I/O is bad. In fact, Postgres also stores just how closely, or badly those pointers correspond to the underlying order on the heap for that column via something called correlation. So if, somehow, the book entries in the heap just happened to be stored (more or less) in increasing values of pages, there would be a high correlation on the pages column, and this index would be more likely to be used for this query.
For these reasons, Postgres thought it would be better to use the index to only keep track of which heap locations had relevant records, and then fetch those heap locations in heap order, after the Bitmap scan sorted them. This results in neighboring chunks of memory in the heap being pulled together, rather than frequently following those random pointers from the index.
Again, Random I/O tends to be expensive and can hurt query performance. This was not faulty reasoning at all.
But in this case Postgres wagered wrong. Our query now runs slower than the regular table scan from before, on the same query. It now takes 1.38 seconds, instead of 833ms. Adding an index made this query run slower.
Was I forcing the issue with the larger limit of 100,000? Of course. My goal is to show how indexes work, how they can help, and occasionally, how they can lead the query optimizer to make the wrong choice, and hurt performance. But please don’t think an index causing a worse, slower execution plan is an unhinged, unheard of eventuality which I contrived for this post; I’ve seen it happen on very normal queries on production databases.
The road not traveled
Can we force Postgres to do a regular index scan, to see what might have been? It turns out we can; we can (temporarily) turn off bitmap scans, and run the same query.
SET enable_bitmapscan = off;
explain analyze
select title, pages
from books
where pages > 697
limit 100000;
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)and now our query runs in just 309ms

Clearly Postgres’s statistics led it astray this time. They’re based on heuristics and probabilities, along with estimated costs for things like disk access. It won’t always work perfectly.
When stats get things right
Before we move on, let’s query all the books with an above-average number of pages
explain analyze
select title, pages
from books
where pages > 400
limit 100000;
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)In this case Postgres was smart enough to not even bother with the index.

Postgres’ statistics told it that this query would match an enormous number of rows, and just walking across the heap would get it the right results more quickly than bothering with the index. And in this case it assumed correctly. The query ran in just 37ms.
Covering Indexes
Let’s go back to this query
explain analyze
select title, pages
from books
where pages > 697
limit 100000;
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)It took a little over 800ms with no index, and over 1.3 seconds with an index on just pages.
The shortcoming of our index was that it did not include title, which is needed for this query; Postgres had to keep running to the heap to retrieve it.
Your first instinct might be to just add title to the index.
CREATE INDEX idx_pages_title ON books(pages, title);
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)Which would look like this:

This would work fine. We’re not needing to filter based on title, only pages. But having those titles in the gold non-leaf nodes wouldn’t hurt one bit. Postgres would just ignore it, find the starting point for all books with > 400 pages, and start reading. There’s be no need for heap access at all, since the titles are right there.
Let’s try it.

Our query now runs in just 32ms! And we have a new operation in our execution plan.
-> Index Only Scan using idx_pages_title on books (cost=0.69..30393.42 rows=451013 width=73) (actual time=0.243..83.911 rows=453891 loops=1)
Index Only Scan means that only the index is being scanned. Again, there’s no need to look anything up in the heap, since the index has all that we need. That makes this a “covering index” for this query, since the index can “cover” it all.
More or less.
Heap Fetches: 0
That’s Line 4 above, and it is not as redundant as it might seem. Postgres does have to consult something called a visibility table to make sure the values in your index are up to date given how Postgres handles updates through it’s MVCC system. If those values are not up to date, it will have to hit the heap. But unless your data are changing extremely frequently this should not be a large burden.
In this case, it turns out Postgres had to go to the heap zero times.
A variation on the theme
If you’re using Postgres or Microsoft SQL Server you can create an even nicer version of this index. Remember, we’re not actually querying on title here, at all. We just put it in the index so the title values would be in the leaf nodes, so Postgres could read them, without having to visit the heap.
Wouldn’t it be nice it we could only put those titles in the leaf nodes? This would keep our internal nodes smaller, with less content, which, in a real index, would let us cram more key values together, resulting in a smaller, shallower B Tree that would potentially be faster to query.
We do this with the INCLUDE clause when creating our index (in databases that support this feature).
CREATE INDEX idx_pages_include_title ON books(pages) INCLUDE(title);
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)This tell Postgres to create our index on the pages column, as before, but also include the title field in the leaf nodes. It would look like this, conceptually.

And re-running that same query, we see that it does run a bit faster. From 32ms down to just 21ms.

To be clear, it’s quite fast either way, but a nice 31% speedup isn’t something to turn down if you’re using a database that supports this feature (MySQL does not).
Pay attention to your SELECT clauses
There’s one corollary to the above: don’t request things you don’t need in your queries; don’t default to SELECT *
Requesting only what you need will not only reduce the amount of data that has to travel over the wire, but in extreme cases can mean the difference between an index scan, and an index-only scan. In the above query, if we’d done SELECT * instead of SELECT title, pages, none of the indexes we added would have been able to help; those heap accesses would have continued to hurt us.
Wrapping up
To say that this post is only scratching the surface would be an understatement. The topic of indexing, and query optimization could fill entire books, and of course it has.
Hopefully, this post has you thinking about indexes the right way. Thinking about how indexes are stored on disk, and how they’re read. And never, ever forgetting about the fact that, when scanning an index, you may still need to visit the heap for every matched entry you find, which can get expensive.
Editor’s note: our The Complete Course for Building Backend Web Apps with Go includes setting up a PostgreSQL database and running it in Docker, all from scratch.
Hi Adam,
I am attempting to create and setup the database using your github sql scripting, but I am encountering difficulty in configuring using my DBeaver SQL Manager Studio which is linked to the Postgres local host.
At this time, my default connection is the default schema labeled public, and so I am unsure how to proceed further here:
I’m really not sure. You’ll need to have Postgres running somewhere, and then connect to it. You could spin up a DB with Supabase and follow their instructions for connecting. Or you could just use Docker, which is what I did for this post
docker container run -e POSTGRES_USER=docker -e POSTGRES_PASSWORD=docker -p 5432:5432 -v /Users/arackis/Documents/pg-data:/var/lib/postgresql/data postgres:17.5-alpine3.22
just change the mounted volume path accordingly, for your machine, and then connect via psql
psql postgresql://docker:docker@localhost:5432
Super useful! Thank you Adam!