Neon
Complete Intro to Databases

7 hours, 4 minutes
CC

Course Description
Databases can seem like big, insurmountable obstacles when learning to become a full-stack developer. In this course, you'll learn the basics of using four of the most popular open-source types of databases: document-based database MongoDB, relational database PostgreSQL, graph database Neo4j, and key-value store Redis. And how and when you'd use each database!
This course and others like it are available as part of our Frontend Masters video subscription.
Preview
CloseWhat They're Saying
Having been focused on Front End these last years, this course is amazing to get your hands dirty not only in the usual SQL and NoSQL stuff but also with other types of DBs. I'm happy to say that I'm confident again in writing queries and glad to recommend this course to rusty people like me or newcomers to the topic!

Bruno Alberto Becerra Gomez
This course gave me a better understanding of databases and their core functionalities. I think the knowledge I gained from this course will help me choose the right databases for different projects and work with them seamlessly.

Hasitha Peiris
I just completed "Complete Intro to Databases" by Brian Holt on Frontend Masters! Great refresher on things I knew, and the new concepts and perspective of how things should be is just invaluable! Good one 🙂

Abu Talha
rogdex24

Course Details
Published: December 8, 2020
Rating
Learning Paths
Topics
Learn Straight from the Experts Who Shape the Modern Web
Your Path to Senior Developer and Beyond
- 200+ In-depth courses
- 18 Learning Paths
- Industry Leading Experts
- Live Interactive Workshops
Table of Contents
Introduction
Section Duration: 25 minutes
 Brian Holt lists the prerequisites necessary to understand this course, shares the course resouces, and gives an overview of past professional experiences.
Brian Holt lists the prerequisites necessary to understand this course, shares the course resouces, and gives an overview of past professional experiences. Brian introduces the four types of databases that the course covers, MongoDB, PostgreSQL, Neo4j, and Redis, and adds that Docker is used in this course to manage the various databases.
Brian introduces the four types of databases that the course covers, MongoDB, PostgreSQL, Neo4j, and Redis, and adds that Docker is used in this course to manage the various databases. Brian defines a database as a place to store data, explains that a schema is used, explores the various types of databases, and discusses when it is best practice to use them. The ACID acronym and database transactions are also explored in this segment, particularly around their usefulness relating to queries.
Brian defines a database as a place to store data, explains that a schema is used, explores the various types of databases, and discusses when it is best practice to use them. The ACID acronym and database transactions are also explored in this segment, particularly around their usefulness relating to queries.
NoSQL
Section Duration: 1 hour, 52 minutes
 Brian explains that "NoSQL" is a buzzword to describe a database that does not use SQL, even though some NoSQL databases are able to handle SQL queries. NoSQL databases do not require schemas.
Brian explains that "NoSQL" is a buzzword to describe a database that does not use SQL, even though some NoSQL databases are able to handle SQL queries. NoSQL databases do not require schemas. Brian introduces MongoDB, a NoSQL database, demonstrates how to create a MongoDB database using Docker, and defines collections as a group of documents or a group of objects. It is best practice to have one collection to represent objects with the same characteristic. A collection would be a row within a database. Row, record, and document are terms that can be used interchangeably.
Brian introduces MongoDB, a NoSQL database, demonstrates how to create a MongoDB database using Docker, and defines collections as a group of documents or a group of objects. It is best practice to have one collection to represent objects with the same characteristic. A collection would be a row within a database. Row, record, and document are terms that can be used interchangeably.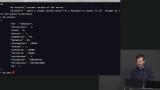 Brian demonstrates how to insert an array of JavaScript objects into a MongoDB database, and shares a few queries that can be used when working with MongoDB. Query operators and how to efficiently use them are also discussed in this segment.
Brian demonstrates how to insert an array of JavaScript objects into a MongoDB database, and shares a few queries that can be used when working with MongoDB. Query operators and how to efficiently use them are also discussed in this segment.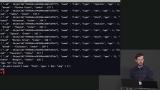 Brian uses logical operators to add conditions to the data queried, and limits the amount of data queried by using a projection. A projection select only the queried data, and not the entire document.
Brian uses logical operators to add conditions to the data queried, and limits the amount of data queried by using a projection. A projection select only the queried data, and not the entire document.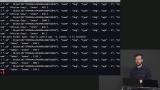 Brian explains that projections are used when engineers query a database but want to limit which fields are returned, and demonstrates how to write projections in a MongoDB database.
Brian explains that projections are used when engineers query a database but want to limit which fields are returned, and demonstrates how to write projections in a MongoDB database. Brian demonstrates how to update an object within MongoDB by first querying the object that needs to be modified, and then modifying that object. The concept of upsert is also discussed in this segment, which is to find an object in a database, and updating it, or if that object does not exist creating it.
Brian demonstrates how to update an object within MongoDB by first querying the object that needs to be modified, and then modifying that object. The concept of upsert is also discussed in this segment, which is to find an object in a database, and updating it, or if that object does not exist creating it.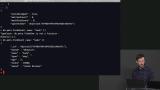 Brian demonstrates how to delete multiple objects from a MongoDB database, and how to find and delete a specific query object based on a given characteristic within the database.
Brian demonstrates how to delete multiple objects from a MongoDB database, and how to find and delete a specific query object based on a given characteristic within the database.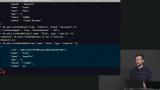 Brian explains that indexes are data structures that a database maintains to allow users to find information quickly by creating a shortcut to specifc data, and runs index queries on the MongoDB database.
Brian explains that indexes are data structures that a database maintains to allow users to find information quickly by creating a shortcut to specifc data, and runs index queries on the MongoDB database.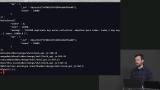 Brian demonstrates how to use text search indexes in MongoDB. A text search is similar to a search one would conduct on a search engine, that would focus and match the key words of a given search.
Brian demonstrates how to use text search indexes in MongoDB. A text search is similar to a search one would conduct on a search engine, that would focus and match the key words of a given search. Brian explains that an aggregation is a feature of MongoDB database, and demonstrates how to write one. An aggregation reduces data until smaller sets of data. A Pipeline is an aggregation that is easier to maintain and that provides filters that transform documents within a collection.
Brian explains that an aggregation is a feature of MongoDB database, and demonstrates how to write one. An aggregation reduces data until smaller sets of data. A Pipeline is an aggregation that is easier to maintain and that provides filters that transform documents within a collection. Brian answers questions about buckets within pipeline aggregations, the various stages within the aggregation pipeline, and the creation time of a given object in a MongoDB database.
Brian answers questions about buckets within pipeline aggregations, the various stages within the aggregation pipeline, and the creation time of a given object in a MongoDB database. Brian demonstrates how to create a bare bone Node.js application that searches for data within a MongoDB database.
Brian demonstrates how to create a bare bone Node.js application that searches for data within a MongoDB database. Brian demonstrates how to use Mongoose and Express to connect to the MongoDB database, and how to query the database using the Node.js application started in the previous segment.
Brian demonstrates how to use Mongoose and Express to connect to the MongoDB database, and how to query the database using the Node.js application started in the previous segment. Brian demonstrates how to run a MongoDB cluster after giving an overview of what primaries, secondaries, and replica set servers are. Sharding is also discussed in this segment.
Brian demonstrates how to run a MongoDB cluster after giving an overview of what primaries, secondaries, and replica set servers are. Sharding is also discussed in this segment.
SQL
Section Duration: 1 hour, 59 minutes
 Brian defines SQL databases as relational databases, frequently abbreviated as RDBMS, or relational database management system. SQL stands for standard query language. A relational database is a set of tables that contains columns and rows, and that has a defined schema.
Brian defines SQL databases as relational databases, frequently abbreviated as RDBMS, or relational database management system. SQL stands for standard query language. A relational database is a set of tables that contains columns and rows, and that has a defined schema. Brian demonstrates how to create and run a PostgreSQL database inside of a Docker container. The database created is a sample PostgreSQL message board database containing various boards, messages, users, and comments.
Brian demonstrates how to create and run a PostgreSQL database inside of a Docker container. The database created is a sample PostgreSQL message board database containing various boards, messages, users, and comments. Brian demonstrates how to create a table, add it to the message database created in the previous segment, and how to insert a new record into the database.
Brian demonstrates how to create a table, add it to the message database created in the previous segment, and how to insert a new record into the database.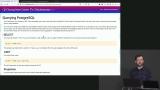 Brian adds data in bulk to the PostgreSQL database created earlier, and demonstrates how to select data, use the limit keyword to limit the amount of data queried, and delete data from the message board database.
Brian adds data in bulk to the PostgreSQL database created earlier, and demonstrates how to select data, use the limit keyword to limit the amount of data queried, and delete data from the message board database.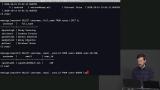 Brian demonstrates some basic operations that can be made on the data in a PostgreSQL database, including using the WHERE command to filter data, the COUNT command to check how many users are in the database, how to update data, and how to delete data in a PostgreSQL database.
Brian demonstrates some basic operations that can be made on the data in a PostgreSQL database, including using the WHERE command to filter data, the COUNT command to check how many users are in the database, how to update data, and how to delete data in a PostgreSQL database.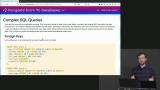 Brian explains that foreign keys are a reference to one table located within another table, and walks through the various tables that are within the example message boards database and that contain foreign keys.
Brian explains that foreign keys are a reference to one table located within another table, and walks through the various tables that are within the example message boards database and that contain foreign keys. Brian explains that one of the advantages of working with an SQL database is the option of using JOIN, and demonstrates how JOIN can be useful by joining two tables, the comments and users example tables.
Brian explains that one of the advantages of working with an SQL database is the option of using JOIN, and demonstrates how JOIN can be useful by joining two tables, the comments and users example tables.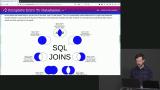 Brian explores and explains the use of the three most used SQL joins: INNER JOIN, RIGHT JOIN, and LEFT JOIN. The other less popular SQL joins are also briefly discussed in this segment.
Brian explores and explains the use of the three most used SQL joins: INNER JOIN, RIGHT JOIN, and LEFT JOIN. The other less popular SQL joins are also briefly discussed in this segment. Brian explains that GROUP BY is a command that allows engineers to determine how to group query results by chosen values, and is used in the example of the board messaging database to query the top 10 most commented on message boards. How to use GROUP BY with the SELECT, INNER JOIN and COUNT commands is also discussed in this segment.
Brian explains that GROUP BY is a command that allows engineers to determine how to group query results by chosen values, and is used in the example of the board messaging database to query the top 10 most commented on message boards. How to use GROUP BY with the SELECT, INNER JOIN and COUNT commands is also discussed in this segment. Brian explains that PostgreSQL has a JSON datatype, demonstrates how to query JSON data stored in the message boards database, and how to write multi-leveled data query when trying to access data within a JSON file that is included in a PostgreSQL database.
Brian explains that PostgreSQL has a JSON datatype, demonstrates how to query JSON data stored in the message boards database, and how to write multi-leveled data query when trying to access data within a JSON file that is included in a PostgreSQL database. Brian demonstrates how to use indexes in PostgreSQL to speed up the process of looking for specific data. When using indexes PostgreSQL decides which scan to use to complete the query and create a shortcut or a tree. PostgreSQL can select which scan an index uses, namely a bitmap heap scan node or an index scan.
Brian demonstrates how to use indexes in PostgreSQL to speed up the process of looking for specific data. When using indexes PostgreSQL decides which scan to use to complete the query and create a shortcut or a tree. PostgreSQL can select which scan an index uses, namely a bitmap heap scan node or an index scan.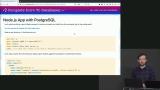 Brian starts to build a similar Node.js application to the one build in the previous section, but uses PostgreSQL instead of MongoDB, demonstrates how add a PostgreSQL query into the server code so that only a specific portion of the database is targeted and accessible.
Brian starts to build a similar Node.js application to the one build in the previous section, but uses PostgreSQL instead of MongoDB, demonstrates how add a PostgreSQL query into the server code so that only a specific portion of the database is targeted and accessible.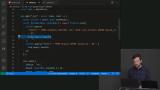 Brian explains that SQL injection happens when users can add input that is interpreted by the database as SQL, and can therefore modify the data within a given database. Parameterized queries block SQL injections by not allowing any SQL queries into a user input field.
Brian explains that SQL injection happens when users can add input that is interpreted by the database as SQL, and can therefore modify the data within a given database. Parameterized queries block SQL injections by not allowing any SQL queries into a user input field.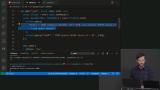 Brian explains that Hasura transforms a database into a GraphQL endpoint, and adds that GraphQL can be combined with Apollo or other interfaces that will link GraphQL to the frontend of a given application.
Brian explains that Hasura transforms a database into a GraphQL endpoint, and adds that GraphQL can be combined with Apollo or other interfaces that will link GraphQL to the frontend of a given application. Brian reviews the most common terms of Postgres Ops used by database administrators, and recommends additional resources where students can gain more knowledge on the subject.
Brian reviews the most common terms of Postgres Ops used by database administrators, and recommends additional resources where students can gain more knowledge on the subject.
Graph
Section Duration: 1 hour, 16 minutes
 Brian explains that graph databases are used to represent data that has complex relationships with other data within a given database, and adds that a node is a graph database that represents an entity. Multiple nodes have relationships or edges between each other. Neo4j is the graph database used in this section.
Brian explains that graph databases are used to represent data that has complex relationships with other data within a given database, and adds that a node is a graph database that represents an entity. Multiple nodes have relationships or edges between each other. Neo4j is the graph database used in this section. Brian introduces Neo4j, a graph database, and demonstrates how to create and connect to a Neo4j database using Docker.
Brian introduces Neo4j, a graph database, and demonstrates how to create and connect to a Neo4j database using Docker. Brian explains that Cypher is the query language used for Neo4j, demonstrates how to add data to the Neo4j database, how to create a node, and how to add relationships to a given node. Data about the movie Scott Pilgrim vs. the World is added to the Neo4j database.
Brian explains that Cypher is the query language used for Neo4j, demonstrates how to add data to the Neo4j database, how to create a node, and how to add relationships to a given node. Data about the movie Scott Pilgrim vs. the World is added to the Neo4j database.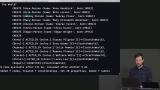 Brian demonstrates how to query for relationships between nodes using the MATCH command. The MATCH command is used to find who acted in the movie added to the database in the previous segment. How to use the CONSTRAINT command to filter out movies with the same title is also mentioned here.
Brian demonstrates how to query for relationships between nodes using the MATCH command. The MATCH command is used to find who acted in the movie added to the database in the previous segment. How to use the CONSTRAINT command to filter out movies with the same title is also mentioned here.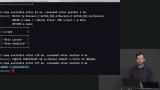 Brian demonstrates how to get a visual representation of the various nodes and relationships of a Neo4j database in a browser, and how to add additional data to the database through a browser.
Brian demonstrates how to get a visual representation of the various nodes and relationships of a Neo4j database in a browser, and how to add additional data to the database through a browser.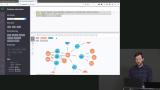 Brian demonstrates how to use the use shortest path feature in the Neo4j database that uses a path algorithm on a database. A path is a data structure that allows engineers to find existing relationships between two nodes in the database. The example Brian gives is the number of degrees of distance between actors and Kevin Bacon.
Brian demonstrates how to use the use shortest path feature in the Neo4j database that uses a path algorithm on a database. A path is a data structure that allows engineers to find existing relationships between two nodes in the database. The example Brian gives is the number of degrees of distance between actors and Kevin Bacon.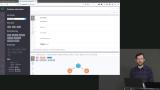 Brian demonstrates how to use another algorithm in an Neo4j database, the recommendation algorithm, which allows engineers to generate movie recommendations by finding which actors partnered the most with a given actor, and recommending their movies.
Brian demonstrates how to use another algorithm in an Neo4j database, the recommendation algorithm, which allows engineers to generate movie recommendations by finding which actors partnered the most with a given actor, and recommending their movies. Brian explains that like a PostgreSQL or a MongoDB database, some queries in Neo4j could be costly to a given organization, and that the solution is to use indexes. Brian also demonstrates how to use indexes in a Neo4j database.
Brian explains that like a PostgreSQL or a MongoDB database, some queries in Neo4j could be costly to a given organization, and that the solution is to use indexes. Brian also demonstrates how to use indexes in a Neo4j database.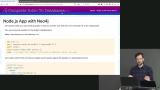 Brian demonstrates how to create a Node.js application and adds a query to the server that fetches data from a Neo4j database.
Brian demonstrates how to create a Node.js application and adds a query to the server that fetches data from a Neo4j database. Brian explains how a Neo4j database can run with no cost in production, as long as the team only uses one server.
Brian explains how a Neo4j database can run with no cost in production, as long as the team only uses one server.
Key-Value Store
Section Duration: 1 hour, 15 minutes
 Brian explains that key-value store databases are rarely used as the only database in a company, and are generally used for data that is less important like cache data. This section focuses on Redis, a key-value store database. but in this segment Brian introduces other key-value store databases that could also be used. How to set and get data from a Redis store is also discussed in this segment.
Brian explains that key-value store databases are rarely used as the only database in a company, and are generally used for data that is less important like cache data. This section focuses on Redis, a key-value store database. but in this segment Brian introduces other key-value store databases that could also be used. How to set and get data from a Redis store is also discussed in this segment.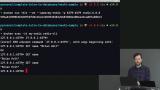 Brian explains how namespaces are used to avoid name collision within a key-value store database, and demonstrates how to use namespaces in a Redis database.
Brian explains how namespaces are used to avoid name collision within a key-value store database, and demonstrates how to use namespaces in a Redis database.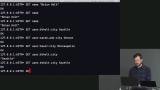 Brian demonstrates how Redis can execute some mathematical commands by increasing, decreasing, adding or subtracting key values that are integers, and shares a few example commands.
Brian demonstrates how Redis can execute some mathematical commands by increasing, decreasing, adding or subtracting key values that are integers, and shares a few example commands.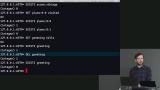 Brian continues sharing commands that are useful to engineers when using Redis. Writing conditional queries and TTLs are discussed. TTLs or Time to Live set elements of a Redis database to expire. For instance, using TTL with cache determines when the cache will be deleted. The concept of a thundering herd, and how to avoid it, are also discussed in the segment.
Brian continues sharing commands that are useful to engineers when using Redis. Writing conditional queries and TTLs are discussed. TTLs or Time to Live set elements of a Redis database to expire. For instance, using TTL with cache determines when the cache will be deleted. The concept of a thundering herd, and how to avoid it, are also discussed in the segment.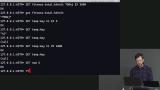 Brian demonstrates how to use the list data type on Redis, and creates a list of notifications that is linked to a given user. Notifications are an example of data that can be stored using Redis, because the loss of notifications would not be a drastic loss of data within a given application. Hash and set datatypes in Redis are also discussed in this segment.
Brian demonstrates how to use the list data type on Redis, and creates a list of notifications that is linked to a given user. Notifications are an example of data that can be stored using Redis, because the loss of notifications would not be a drastic loss of data within a given application. Hash and set datatypes in Redis are also discussed in this segment.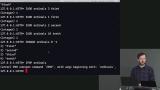 Brian defines HyperLogLog as a command used to check if an element does not exist in the database, and explains that streams are useful when adding an important amount of data to a source, and needing to subscribe to updates of that data.
Brian defines HyperLogLog as a command used to check if an element does not exist in the database, and explains that streams are useful when adding an important amount of data to a source, and needing to subscribe to updates of that data.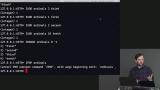 Brian explains that Redis has the ability to evaluate Lua, a scripting language, adds that when engineers need Redis to accept entire programs they use Lua, and demonstrates how to use the Lua language in a Redis database. The least recently used data, or LRU, and how Redis has the capacity to delete it from a database is also discussed in this segment.
Brian explains that Redis has the ability to evaluate Lua, a scripting language, adds that when engineers need Redis to accept entire programs they use Lua, and demonstrates how to use the Lua language in a Redis database. The least recently used data, or LRU, and how Redis has the capacity to delete it from a database is also discussed in this segment.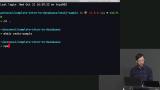 Brian builds a page counter Node.js application that uses a Redis database, and uses the promisify function to be able to use promises within the server instead of callbacks. Redis only understands callbacks.
Brian builds a page counter Node.js application that uses a Redis database, and uses the promisify function to be able to use promises within the server instead of callbacks. Redis only understands callbacks.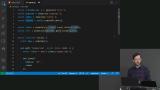 Brian demonstrates how to combine PostgresSQL and Redis by adding caching to a PostgresSQL query that takes a long time to complete. A higher order function cache sends a cached response while the PostgresSQL query is running.
Brian demonstrates how to combine PostgresSQL and Redis by adding caching to a PostgresSQL query that takes a long time to complete. A higher order function cache sends a cached response while the PostgresSQL query is running.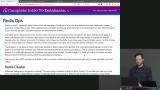 Brian explains that, similarly to Neo4j, Redis has a primary and a secondary configuration. The preferred terms used are leader and follower.
Brian explains that, similarly to Neo4j, Redis has a primary and a secondary configuration. The preferred terms used are leader and follower.
Wrapping Up
Section Duration: 13 minutes
 Brian walks through the process of choosing a database for a given application or project, evaluates the tradeoffs of each choice, mentions other courses available on Frontend Masters that tackle backend technology, and thanks the audience. Questions about data migration are also answered in this segment.
Brian walks through the process of choosing a database for a given application or project, evaluates the tradeoffs of each choice, mentions other courses available on Frontend Masters that tackle backend technology, and thanks the audience. Questions about data migration are also answered in this segment.
Learn Straight from the Experts Who Shape the Modern Web
- In-depth Courses
- Industry Leading Experts
- Learning Paths
- Live Interactive Workshops