zed.dev
Write a Compiler That Understands Types

4 hours, 50 minutes
CC

Course Description
Ever wonder how TypeScript figures out types? Type inference might seem like magic, but you'll implement it step by step using the powerful Hindley-Milner system. Construct each part of a working compiler, including parsing, scope resolution, type inference, and bytecode generation. Deepen your understanding of language design and compiler internals by building a type system from scratch!
Prerequisite: JavaScript Learning Path or strong JavaScript experience and familiarity with data structures and recursion.
Preview
Course Details
Published: June 10, 2025
Rating
Learning Paths
Learn Straight from the Experts Who Shape the Modern Web
Your Path to Senior Developer and Beyond
- 250+ In-depth courses
- 24 Learning Paths
- Industry Leading Experts
- Live Interactive Workshops
Table of Contents
Introduction
Section Duration: 16 minutes
 Richard Feldman introduces the course by giving historical context for compilers and explaining how compilers transform code into machine instructions, covering interpreters, JITs, transpilers, and bytecode. He also provides a brief look at WebAssembly, which the course’s final compiler will target directly.
Richard Feldman introduces the course by giving historical context for compilers and explaining how compilers transform code into machine instructions, covering interpreters, JITs, transpilers, and bytecode. He also provides a brief look at WebAssembly, which the course’s final compiler will target directly. Richard introduces key compilation concepts and terminology like name resolution and type inference, and explains the difference between compilers, transpilers, and interpreters. He also outlines the course plan to build a simple compiler that ends with WebAssembly output.
Richard introduces key compilation concepts and terminology like name resolution and type inference, and explains the difference between compilers, transpilers, and interpreters. He also outlines the course plan to build a simple compiler that ends with WebAssembly output.
Traversing the AST
Section Duration: 36 minutes
 Richard discusses the process of lexing, parsing, and formatting in compilers. Lexing involves converting source code into tokens, parsing involves creating a parse tree from tokens, and formatting involves generating output strings from the parse tree.
Richard discusses the process of lexing, parsing, and formatting in compilers. Lexing involves converting source code into tokens, parsing involves creating a parse tree from tokens, and formatting involves generating output strings from the parse tree. Richard walks through the formatter exercise comments with instructions to make changes to resolve failing tests. The exercises involve formatting array literals, call expressions, and binary expressions by iterating over parse tree nodes. Richard also discusses potential edge cases and considerations in compiler development, such as stack safety and handling different function call scenarios.
Richard walks through the formatter exercise comments with instructions to make changes to resolve failing tests. The exercises involve formatting array literals, call expressions, and binary expressions by iterating over parse tree nodes. Richard also discusses potential edge cases and considerations in compiler development, such as stack safety and handling different function call scenarios.
Bindings & Scope Resolution
Section Duration: 26 minutes
 Richard discusses name resolution in compilers, focusing on declarations, lookups, hoisting, and nested scopes. He explains how scopes are managed, handling naming errors, duplicate declarations, and shadowing. Richard also discusses nested scopes and how to handle variable visibility within different nested levels.
Richard discusses name resolution in compilers, focusing on declarations, lookups, hoisting, and nested scopes. He explains how scopes are managed, handling naming errors, duplicate declarations, and shadowing. Richard also discusses nested scopes and how to handle variable visibility within different nested levels. Richard discusses hoisting, where functions can be called before they are declared, and explains a two-pass approach to handle hoisting by adding functions to the scope first before processing other declarations. He also covers declarations, lookups, and nested scopes in programming languages, emphasizing the importance of managing scopes during compilation.
Richard discusses hoisting, where functions can be called before they are declared, and explains a two-pass approach to handle hoisting by adding functions to the scope first before processing other declarations. He also covers declarations, lookups, and nested scopes in programming languages, emphasizing the importance of managing scopes during compilation. Richard introduces the name resolution exercise, focusing on implementing naming conventions and scoping rules. He also walks through the solutions by updating functions like declare variable, adding variables to scope, and visiting binary expressions and arrow functions.
Richard introduces the name resolution exercise, focusing on implementing naming conventions and scoping rules. He also walks through the solutions by updating functions like declare variable, adding variables to scope, and visiting binary expressions and arrow functions.
Type Inference
Section Duration: 1 hour, 18 minutes
 Richard explains the foundational concepts of type checking, focusing on Hindley-Milner type inference used in languages like Elm and Haskell. He highlights the benefits of Hindley-Milner, such as soundness, decidable inference, and support for parametric polymorphism without incurring performance penalties.
Richard explains the foundational concepts of type checking, focusing on Hindley-Milner type inference used in languages like Elm and Haskell. He highlights the benefits of Hindley-Milner, such as soundness, decidable inference, and support for parametric polymorphism without incurring performance penalties. Richard explains the process of inferring constants in a compiler by using a types database to establish relationships between variables. By assigning type variables to nodes in the parse tree and creating links between them, the compiler can infer the types of variables through transitive relationships.
Richard explains the process of inferring constants in a compiler by using a types database to establish relationships between variables. By assigning type variables to nodes in the parse tree and creating links between them, the compiler can infer the types of variables through transitive relationships. Richard discusses the concept of path compression in type inference and how it optimizes compiler performance by reducing the number of hops needed to determine types. Path compression involves updating database values to point directly to the final type, leveraging the unification property in Hindley-Milner type inference.
Richard discusses the concept of path compression in type inference and how it optimizes compiler performance by reducing the number of hops needed to determine types. Path compression involves updating database values to point directly to the final type, leveraging the unification property in Hindley-Milner type inference. Richard introduces the type check exercises, focusing on resolving failing tests by working with type IDs in the type database, visiting nodes to populate type information, and updating scopes with type IDs. He also walks through the solutions, finding and storing type IDs for parse tree nodes, linking them to scope entries, and recording them in nodes for future reference.
Richard introduces the type check exercises, focusing on resolving failing tests by working with type IDs in the type database, visiting nodes to populate type information, and updating scopes with type IDs. He also walks through the solutions, finding and storing type IDs for parse tree nodes, linking them to scope entries, and recording them in nodes for future reference. Richard covers type unification by demonstrating how operators like plus and times require their operands to unify with specific types, such as numbers. He also explains how the unify function resolves type variables by traversing type links, imposing multiple constraints simultaneously, and detecting type mismatches that get reported at compile time.
Richard covers type unification by demonstrating how operators like plus and times require their operands to unify with specific types, such as numbers. He also explains how the unify function resolves type variables by traversing type links, imposing multiple constraints simultaneously, and detecting type mismatches that get reported at compile time.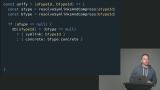 Richard answers student questions regarding how type unification resolves null and concrete types in a static type inference system. He explains the process of linking type variables, handling argument symmetries, detecting type mismatches, and the role of occurs checks in preventing infinite loops during compilation.
Richard answers student questions regarding how type unification resolves null and concrete types in a static type inference system. He explains the process of linking type variables, handling argument symmetries, detecting type mismatches, and the role of occurs checks in preventing infinite loops during compilation. Richard provides a brief summary of part 4, including unifying operators, type mismatches, and the unify() function. He also walks through the unify multiplication operator exercise and solution involving the multiplication operator in typecheck.js, showcasing the process of handling concrete and non-concrete types in the context of operators.
Richard provides a brief summary of part 4, including unifying operators, type mismatches, and the unify() function. He also walks through the unify multiplication operator exercise and solution involving the multiplication operator in typecheck.js, showcasing the process of handling concrete and non-concrete types in the context of operators.
Inferring Types
Section Duration: 42 minutes
 Richard discusses inferring functions, starting with conditionals, which serve as an introduction to inferring functions. He also explains the process of inferring function declarations and function calls, emphasizing the need for type consistency within conditionals and the unification of types in programming.
Richard discusses inferring functions, starting with conditionals, which serve as an introduction to inferring functions. He also explains the process of inferring function declarations and function calls, emphasizing the need for type consistency within conditionals and the unification of types in programming. Richard explains inferring functions by breaking down the components of a function, such as arguments, return types, and expressions. He also demonstrates unifying different types within a function, like linking arguments to numbers and handling return types.
Richard explains inferring functions by breaking down the components of a function, such as arguments, return types, and expressions. He also demonstrates unifying different types within a function, like linking arguments to numbers and handling return types. Richard discusses maintaining consistency between function calls, arguments, and return types to avoid type mismatches. He also discusses handling type errors by continuing the unification process to provide comprehensive error messages.
Richard discusses maintaining consistency between function calls, arguments, and return types to avoid type mismatches. He also discusses handling type errors by continuing the unification process to provide comprehensive error messages. Richard guides students through the inferring functions exercise including creating a new row in the database table for unification purposes, differentiating between scenarios involving parentheses and identifiers when calling functions, and handling return type information.
Richard guides students through the inferring functions exercise including creating a new row in the database table for unification purposes, differentiating between scenarios involving parentheses and identifiers when calling functions, and handling return type information.
Polymorphism & Type Signatures
Section Duration: 48 minutes
 Richard discusses polymorphic type inference by demonstrating how type unification enables correct inference in identity functions without mismatches. He also introduces an example involving an array concatenation function to show how the same type inference process naturally extends to generics like arrays.
Richard discusses polymorphic type inference by demonstrating how type unification enables correct inference in identity functions without mismatches. He also introduces an example involving an array concatenation function to show how the same type inference process naturally extends to generics like arrays. Richard explains the function for concatenating arrays, highlighting the need to handle different types without mismatches. Richard emphasizes the process of unification, the role of type annotations as constraints, and the principles of decidable and principle decidable type inference in Hindley-Milner type systems.
Richard explains the function for concatenating arrays, highlighting the need to handle different types without mismatches. Richard emphasizes the process of unification, the role of type annotations as constraints, and the principles of decidable and principle decidable type inference in Hindley-Milner type systems. Richard introduces type annotations and explains why they can be helpful as verified constraints. He also demonstrates how annotations unify with inferred types, how they can make types less flexible, and what “principle decidable type inference” means in practice.
Richard introduces type annotations and explains why they can be helpful as verified constraints. He also demonstrates how annotations unify with inferred types, how they can make types less flexible, and what “principle decidable type inference” means in practice. Richard walks through the polymorphic type checking exercises by implementing type inference for arrays. He explains how the type checker ensures that all elements in a homogeneous array unify to the same type, using a simple approach of comparing each element to the first.
Richard walks through the polymorphic type checking exercises by implementing type inference for arrays. He explains how the type checker ensures that all elements in a homogeneous array unify to the same type, using a simple approach of comparing each element to the first.
Generating WASM
Section Duration: 28 minutes
 Richard discusses generating web assembly, including generating bytecode, a code tour, and generating polymorphic functions. He also highlights the differences between generating bytecode and human-readable code, such as the use of magic numbers and structural changes required for WebAssembly.
Richard discusses generating web assembly, including generating bytecode, a code tour, and generating polymorphic functions. He also highlights the differences between generating bytecode and human-readable code, such as the use of magic numbers and structural changes required for WebAssembly. Richard explains the process of incorporating WebAssembly operations for addition and multiplication. He emphasizes the importance of setting the opCode variable correctly and understanding the order of operations due to Web Assembly's stack machine nature.
Richard explains the process of incorporating WebAssembly operations for addition and multiplication. He emphasizes the importance of setting the opCode variable correctly and understanding the order of operations due to Web Assembly's stack machine nature. Richard mentions the challenge of generating polymorphic functions in WebAssembly due to varying sizes of data types like bool and number. He also discusses two popular approaches to handle this issue: hidden runtime data, involving passing extra metadata at runtime, and monomorphization, creating specialized versions of functions for different data types.
Richard mentions the challenge of generating polymorphic functions in WebAssembly due to varying sizes of data types like bool and number. He also discusses two popular approaches to handle this issue: hidden runtime data, involving passing extra metadata at runtime, and monomorphization, creating specialized versions of functions for different data types.
Wrapping Up
Section Duration: 13 minutes
 Richard provides a comprehensive overview of the course content and recommends classic compiler books and modern alternatives. He also answers student questions regarding how recursive types are handled, LLVM as a compiler backend, and the limitations of type inference.
Richard provides a comprehensive overview of the course content and recommends classic compiler books and modern alternatives. He also answers student questions regarding how recursive types are handled, LLVM as a compiler backend, and the limitations of type inference.