Microsoft
Complete Intro to SQL & PostgreSQL

7 hours, 20 minutes
CC

Course Description
SQL is a timeless skillset you'll find in nearly every modern application! Using the popular PostgreSQL database, you'll learn to set up, model, and query your data through real-world projects. You'll also understand how to model complex relationships in your data and query data from large datasets.
Preview
Course Details
Published: October 3, 2022
Rating
Learning Paths
Learn Straight from the Experts Who Shape the Modern Web
Your Path to Senior Developer and Beyond
- 300+ In-depth courses
- 24 Learning Paths
- Industry Leading Experts
- Live Interactive Workshops
Table of Contents
Introduction
Section Duration: 20 minutes
 Brian Holt walks through the course website and explains how this course is designed for developers who want to know how to use SQL and PostgreSQL.
Brian Holt walks through the course website and explains how this course is designed for developers who want to know how to use SQL and PostgreSQL. Brian explains that Docker allows any computer to run a lightweight emulation of a pre-made environment. Two Docker containers that contain PostgresSQL 14 and prepopulated data are installed and will be used throughout the course.
Brian explains that Docker allows any computer to run a lightweight emulation of a pre-made environment. Two Docker containers that contain PostgresSQL 14 and prepopulated data are installed and will be used throughout the course.
Databases and Tables
Section Duration: 34 minutes
 Brian shares some of the history of SQL and demonstrates how to create a database. The psql client provides a number of built-in commands to navigate and display information about databases and tables. While SQL syntax is case insensitive, SQL commands are typically written in all capital letters.
Brian shares some of the history of SQL and demonstrates how to create a database. The psql client provides a number of built-in commands to navigate and display information about databases and tables. While SQL syntax is case insensitive, SQL commands are typically written in all capital letters. Brian demonstrates how to create a table in a database and adds data to the table. Tables are structured like spreadsheets because they contain rows and columns. The columns are the different fields within the table. The row are individual records of data.
Brian demonstrates how to create a table in a database and adds data to the table. Tables are structured like spreadsheets because they contain rows and columns. The columns are the different fields within the table. The row are individual records of data.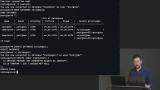 Brian uses the ALTER TABLE command to add and remove columns in the ingredients table. When columns are added to an existing table, default values should be specified to satisfy any NOT NULL constraints.
Brian uses the ALTER TABLE command to add and remove columns in the ingredients table. When columns are added to an existing table, default values should be specified to satisfy any NOT NULL constraints.
SQL Commands
Section Duration: 1 hour, 15 minutes
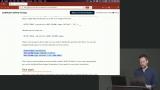 Brian uses the INSERT INTO command to add data to the table. The values for each column should match the order the columns are listed in the insert statement. The ON CONFLICT command indicates how primary key conflicts should be handled.
Brian uses the INSERT INTO command to add data to the table. The values for each column should match the order the columns are listed in the insert statement. The ON CONFLICT command indicates how primary key conflicts should be handled.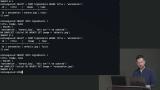 Brian updates existing data by specifying the columns to update and a WHERE clause for the row that should be updated. If the WHERE clause is omitted, all rows will receive the updated value. Deleting data also utilizes a WHERE clause for determining the correct row to remove.
Brian updates existing data by specifying the columns to update and a WHERE clause for the row that should be updated. If the WHERE clause is omitted, all rows will receive the updated value. Deleting data also utilizes a WHERE clause for determining the correct row to remove. Brian introduces the SELECT command and takes a deeper look at WHERE clauses. Conditional operators like >=, <=, and <> can be used to narrow the results. Pagination is implemented by using the LIMIT keyword.
Brian introduces the SELECT command and takes a deeper look at WHERE clauses. Conditional operators like >=, <=, and <> can be used to narrow the results. Pagination is implemented by using the LIMIT keyword.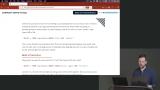 Brian demonstrates how LIKE and ILIKE can be added to a WHERE clause to search for partial strings. SQL functions like LOWER and CONCAT can be combined to create more unique search conditions.
Brian demonstrates how LIKE and ILIKE can be added to a WHERE clause to search for partial strings. SQL functions like LOWER and CONCAT can be combined to create more unique search conditions.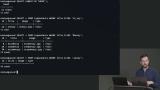 Brian introduces node-postgres which is a collection of node.js modules for interfacing with your PostgreSQL database. One benefit of node-postgres is the ability to prevent SQL injection which happens when a user attempts to pass SQL through a query string. node-postgres will sanitize the query string parameters before running the database query.
Brian introduces node-postgres which is a collection of node.js modules for interfacing with your PostgreSQL database. One benefit of node-postgres is the ability to prevent SQL injection which happens when a user attempts to pass SQL through a query string. node-postgres will sanitize the query string parameters before running the database query. Students are instructed to use node-postgres to implement the ingredients API in the application. Instructions are located in the code comments in /ingredients/API.js. Installation instructions and troubleshooting tips are also included in this lesson.
Students are instructed to use node-postgres to implement the ingredients API in the application. Instructions are located in the code comments in /ingredients/API.js. Installation instructions and troubleshooting tips are also included in this lesson.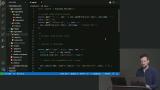 Brian walks through the solution to the Ingredients API exercise.
Brian walks through the solution to the Ingredients API exercise.
Joins and Constraints
Section Duration: 1 hour, 14 minutes
 Brian explains database relationships and demonstrates inner joins. IDs from one table are stored in a column of another table and used to display a combination of columns from both tables. With inner join, if any data is missing from either table, the entire row is omitted from the resulting dataset.
Brian explains database relationships and demonstrates inner joins. IDs from one table are stored in a column of another table and used to display a combination of columns from both tables. With inner join, if any data is missing from either table, the entire row is omitted from the resulting dataset.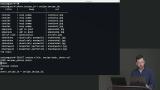 Brian explains the difference between left, right, and full joins. The join direction determines which tables data is included in the dataset and which table data is omitted if a column's value doesn't exist.
Brian explains the difference between left, right, and full joins. The join direction determines which tables data is included in the dataset and which table data is omitted if a column's value doesn't exist.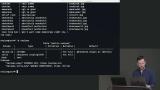 Brian demonstrates natural joins which use columns with the same name to create a join. Cross joins generate a dataset with every permutation between the two joining tables.
Brian demonstrates natural joins which use columns with the same name to create a join. Cross joins generate a dataset with every permutation between the two joining tables.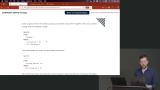 Brian explains how foreign key constraints enforce relationships between tables. Adding an ON DELETE clause will instruct the database on how to handle the removal of foreign keyed items. For example, when a foreign keyed item is removed, the database should remove all other instances of the foreign key from the referenced table.
Brian explains how foreign key constraints enforce relationships between tables. Adding an ON DELETE clause will instruct the database on how to handle the removal of foreign keyed items. For example, when a foreign keyed item is removed, the database should remove all other instances of the foreign key from the referenced table.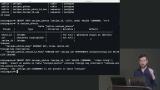 Brian models a many-to-many relationship between the recipies table and the ingredients table. Since one ingredient can belong to many recipes and a recipe has many ingredients, the primary key for the recipe_ingredients table is the combination of a recipe_id and an ingredient_id.
Brian models a many-to-many relationship between the recipies table and the ingredients table. Since one ingredient can belong to many recipes and a recipe has many ingredients, the primary key for the recipe_ingredients table is the combination of a recipe_id and an ingredient_id. Brian uses the CHECK constraint to ensure the type column can only be a specific value.
Brian uses the CHECK constraint to ensure the type column can only be a specific value. Brian demonstrates how to return the first instance of a value by using the DISTINCT constraint. This is useful when a column contains duplicate values and only the first record is required.
Brian demonstrates how to return the first instance of a value by using the DISTINCT constraint. This is useful when a column contains duplicate values and only the first record is required. Students are instructed to implement the search and get recipe by ID APIs. Instructions are located in the code comments in /recipes/API.js.
Students are instructed to implement the search and get recipe by ID APIs. Instructions are located in the code comments in /recipes/API.js. Brian walks through the solution to the Recipes exercise.
Brian walks through the solution to the Recipes exercise.
JSONB
Section Duration: 25 minutes
 Brian explains the JSONB data type is a text field that validates its value as JSON. Additional language features are available to query JSONB columns resulting in simpler SQL statements.
Brian explains the JSONB data type is a text field that validates its value as JSON. Additional language features are available to query JSONB columns resulting in simpler SQL statements.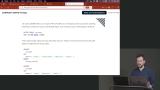 Brian inserts JSONB into the recipes table. Since the column containing the data is of type JSONB, queries are able to return the entire JSONB data set or nested objects from within the data.
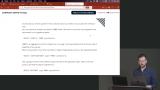
Brian inserts JSONB into the recipes table. Since the column containing the data is of type JSONB, queries are able to return the entire JSONB data set or nested objects from within the data.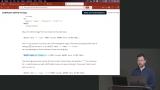 Brian explains the difference between using JSONB in Postgres and a document-based database like MongoDB. Use cases for JSONB are also discussed in this lesson.
Brian explains the difference between using JSONB in Postgres and a document-based database like MongoDB. Use cases for JSONB are also discussed in this lesson.
Aggregation
Section Duration: 12 minutes
 Brian demonstrates the COUNT aggregation function. Rather than return rows of results, the COUNT function can be used to total the number of rows returned by a query or total the number of occurrences of a value in a specific column. Combining COUNT with the GROUP BY clause allows the sum to be displayed along with the specific value.
Brian demonstrates the COUNT aggregation function. Rather than return rows of results, the COUNT function can be used to total the number of rows returned by a query or total the number of occurrences of a value in a specific column. Combining COUNT with the GROUP BY clause allows the sum to be displayed along with the specific value.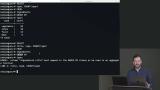 Brian explains how WHERE clauses are executed before aggregate functions. This means WHERE clauses cannot be used to filter aggregated results. The HAVING statement behaves like a WHERE clause, but is executed after the aggregation has occurred. This enables a filter to be applied to the returned data.
Brian explains how WHERE clauses are executed before aggregate functions. This means WHERE clauses cannot be used to filter aggregated results. The HAVING statement behaves like a WHERE clause, but is executed after the aggregation has occurred. This enables a filter to be applied to the returned data.
Functions Triggers and Procedures
Section Duration: 30 minutes
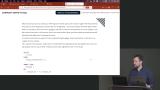 Brian uses a function to store an SQL query so it can be reused and called with different parameters. The programming language used to create the function is plpgsql, however, other languages like Python or JavaScript are supported.
Brian uses a function to store an SQL query so it can be reused and called with different parameters. The programming language used to create the function is plpgsql, however, other languages like Python or JavaScript are supported.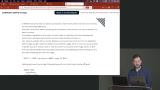 Brian compares functions with procedures. A procedure is designed to do a pre-determined action. However, unlike functions, procedures cannot return data.
Brian compares functions with procedures. A procedure is designed to do a pre-determined action. However, unlike functions, procedures cannot return data.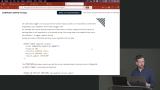 Brian creates a trigger that calls a function whenever a recipe title is updated. Since the trigger is in response to a database update, OLD and NEW variables representing the old and new values are available within the function. Unlike functions or procedures, triggers can only be run by Postgres.
Brian creates a trigger that calls a function whenever a recipe title is updated. Since the trigger is in response to a database update, OLD and NEW variables representing the old and new values are available within the function. Unlike functions or procedures, triggers can only be run by Postgres.
The Movie Database
Section Duration: 46 minutes
 Brian introduces the movie database and reviews the instructions for running the docker container.
Brian introduces the movie database and reviews the instructions for running the docker container. Students are instructed to complete five queries for the movie database. Instructions and hints for each query are located on the course website.
Students are instructed to complete five queries for the movie database. Instructions and hints for each query are located on the course website. Brian demonstrates the solution to "Which movie made the most money?"
Brian demonstrates the solution to "Which movie made the most money?"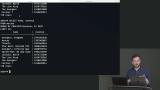 Brian demonstrates the solution to "How much revenue did the movies Keanu Reeves act in make?"
Brian demonstrates the solution to "How much revenue did the movies Keanu Reeves act in make?" Brian demonstrates the solution to "Which 5 people were in the movies that had the most revenue?"
Brian demonstrates the solution to "Which 5 people were in the movies that had the most revenue?" Brian demonstrates the solution to "Which 10 movies have the most keywords?"
Brian demonstrates the solution to "Which 10 movies have the most keywords?" Brian demonstrates the solution to "Which category is associated with the most movies?"
Brian demonstrates the solution to "Which category is associated with the most movies?"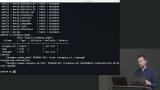 Brian sets up pgAdmin, an open source database administration tool, that provides a graphical user interface for writing queries. Students have the option of writing the remainder of the queries in pgAdmin or using the command line.
Brian sets up pgAdmin, an open source database administration tool, that provides a graphical user interface for writing queries. Students have the option of writing the remainder of the queries in pgAdmin or using the command line.
Query Performance
Section Duration: 49 minutes
 Brian analyzes two queries to demonstrate the performance differences between selecting based on indexed and non-indexed columns. Queries using non-indexed columns are much slower because they require a sequential search which means the query looks through all the rows in the table.
Brian analyzes two queries to demonstrate the performance differences between selecting based on indexed and non-indexed columns. Queries using non-indexed columns are much slower because they require a sequential search which means the query looks through all the rows in the table. Brian shares some background information about how the Postgres planner determines how to execute a query. Using EXPLAIN ANALYZE will break down the query's execution and help identify the areas that need optimization. Adding indexes can help give the query a boost in performance.
Brian shares some background information about how the Postgres planner determines how to execute a query. Using EXPLAIN ANALYZE will break down the query's execution and help identify the areas that need optimization. Adding indexes can help give the query a boost in performance.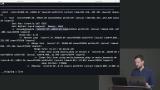 Brian adds an index to the name column in the movies table. The result is a 10x improvement in the query's performance. Other indexing methods including Hash, GiST, SP-GiST and BRIN are also discussed in this lesson.
Brian adds an index to the name column in the movies table. The result is a 10x improvement in the query's performance. Other indexing methods including Hash, GiST, SP-GiST and BRIN are also discussed in this lesson.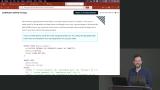 Brian explains GIN indexes are useful for queries where multiple values could apply to one row. The GIN trigram index, which creates three-letter permutations of a search string, is also demonstrated in this lesson.
Brian explains GIN indexes are useful for queries where multiple values could apply to one row. The GIN trigram index, which creates three-letter permutations of a search string, is also demonstrated in this lesson.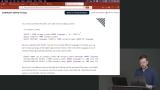 Brian creates a partial index by adding a WHERE clause to the CREATE INDEX statement. This allows a column to be indexed without indexing every row of the column.
Brian creates a partial index by adding a WHERE clause to the CREATE INDEX statement. This allows a column to be indexed without indexing every row of the column.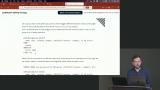 Brian demonstrates how to create an index for a derived value. This can give a significant performance boost to queries returning the result of a function like COALESCE.
Brian demonstrates how to create an index for a derived value. This can give a significant performance boost to queries returning the result of a function like COALESCE.
Views, Subqueries & Arrays
Section Duration: 38 minutes
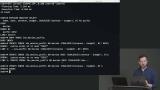 Brian explains how a view is like looking through a lens to the underlying table. They can eliminate complex joins and add a level of security since they are only displaying a subset of the data.
Brian explains how a view is like looking through a lens to the underlying table. They can eliminate complex joins and add a level of security since they are only displaying a subset of the data.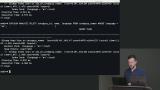 Brian writes a query that joins data between two views. Using views greatly simplifies the query, however, there aren't any performance benefits. Expensive queries will still use a lot of resources and run slowly.
Brian writes a query that joins data between two views. Using views greatly simplifies the query, however, there aren't any performance benefits. Expensive queries will still use a lot of resources and run slowly. Brian demonstrates how to optimize a query using a materialized view. These views are cached so they are very performant. If the data begins to get stale in the materialized view, it can be refreshed and the cache will be updated.
Brian demonstrates how to optimize a query using a materialized view. These views are cached so they are very performant. If the data begins to get stale in the materialized view, it can be refreshed and the cache will be updated. Brian adds an index to the materialized view which leads to a four million percent increase in performance.
Brian adds an index to the materialized view which leads to a four million percent increase in performance. Brian writes a subquery that is nested in the WHERE clause of the original query. Subqueries are an alternative to using multiple INNER JOIN statements which may make the overall query more readable. However, subqueries are typically less performant than joins.
Brian writes a subquery that is nested in the WHERE clause of the original query. Subqueries are an alternative to using multiple INNER JOIN statements which may make the overall query more readable. However, subqueries are typically less performant than joins. Brian uses a subquery to return an Array of data. SQL annotates an Array with curly brackets. An example of referencing tables in the outer query from within the subquery is also shown in this lesson.
Brian uses a subquery to return an Array of data. SQL annotates an Array with curly brackets. An example of referencing tables in the outer query from within the subquery is also shown in this lesson.
Transactions, Window Functions, and Self Join
Section Duration: 28 minutes
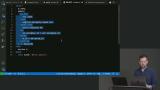 Brian demonstrates how transactions ensure multiple queries run successfully before committing the changes to the database. If any of the queries within the transaction fail, the changes are rolled back. Using functions within a transaction is also demonstrated in this lesson.
Brian demonstrates how transactions ensure multiple queries run successfully before committing the changes to the database. If any of the queries within the transaction fail, the changes are rolled back. Using functions within a transaction is also demonstrated in this lesson.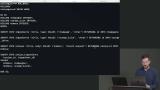 Brian explains window function performs a calculation across a set of table rows that are related to the current row. This is comparable to the type of calculation that can be done with an aggregate function. But unlike regular aggregate functions, the use of a window function does not cause rows to become grouped into a single output row.
Brian explains window function performs a calculation across a set of table rows that are related to the current row. This is comparable to the type of calculation that can be done with an aggregate function. But unlike regular aggregate functions, the use of a window function does not cause rows to become grouped into a single output row. Brian demonstrates how to create a self join by joining a table to itself.
Brian demonstrates how to create a self join by joining a table to itself.
Wrapping Up
Section Duration: 3 minutes
 Brian concludes the course by explaining how knowledge about SQL translates to other areas of development and providing some resources for using the movie database to create a project website.
Brian concludes the course by explaining how knowledge about SQL translates to other areas of development and providing some resources for using the movie database to create a project website.
Earn a Completion Certificate
After completing this course, you'll receive a certificate of completion that serves as proof of your achievement, showcasing your expertise, and commitment to professional development. You can easily share this certificate on your LinkedIn profile to highlight your new skills and demonstrate continuous learning to potential employers and professional connections.

What They're Saying
Really great course, as always! I wanted to take it to get familiar with SQL and I'd say I got much more out of the course, it did exceed my expectations. Loved the practical examples along with all the new concepts, also was great to play around a bit in a NodeJS app to see how all of these concepts look like when you develop an app. I feel like this was foundation course for me to take, as I've been working on web apps for 8 years with only dabbling, and frankly, afraid of DBs. Now I feel well equipped to go build the things which I procrastinated on due to being afraid of SQL and everything near DBs. Thanks to Brian Holt and the entire Master.dev team for another great course, you are doing wonderful educational work.

Vladislav Kovechenkov
I just completed "Complete Intro to SQL & PostgreSQL" by Brian Holt on Master.dev! Excellent course, I learned a ton ✨

Cinder | シンダー
cinderscorner
I just completed "Complete Intro to SQL & PostgreSQL" by Briant Holt on Master.dev! A great refresher course for Postgres and lays the foundation for ORM.

Connie Leung
connieleung404