You Don't Know JS
Exploring Service Workers

4 hours, 15 minutes
CC

Course Description
You’ve likely heard the term “Progressive Web Apps” (PWAs). Sure, it's a buzz word that's a bit overloaded, but it has some great motivations behind it. PWAs represent the dream of web apps getting all the same capabilities, and performance, of native apps. At the core of making this happen is the new Service Workers API. Service Workers give web apps new capabilities to be able to go beyond the browser tab and enable features like smart offline caching and PWA features like push notifications!
Preview
Course Details
Published: July 16, 2019
Rating
Learning Paths
Learn Straight from the Experts Who Shape the Modern Web
Your Path to Senior Developer and Beyond
- 250+ In-depth courses
- 24 Learning Paths
- Industry Leading Experts
- Live Interactive Workshops
Table of Contents
Introduction
Section Duration: 18 minutes
 Kyle Simpson introduces the course on service workers by sharing a few helpful resources and then describing the problems that can be solved with service workers.
Kyle Simpson introduces the course on service workers by sharing a few helpful resources and then describing the problems that can be solved with service workers. Kyle makes a case for service workers by highlighting the responsibility of developers to deliver website experiences thoughtfully.
Kyle makes a case for service workers by highlighting the responsibility of developers to deliver website experiences thoughtfully.
Web Workers
Section Duration: 35 minutes
 Kyle introduces web workers, the precursor to service workers, by explaining their intended usage of handling an offload of heavy processing in a separate thread from the webpage. Child, dedicated, and shared workers are introduced.
Kyle introduces web workers, the precursor to service workers, by explaining their intended usage of handling an offload of heavy processing in a separate thread from the webpage. Child, dedicated, and shared workers are introduced. Kyle introduces the basic parts of the two JavaScript files that will be built upon during the web worker exercise, one to handle events and one to handle processing, and configures the web worker to print a message to the console during initialization.
Kyle introduces the basic parts of the two JavaScript files that will be built upon during the web worker exercise, one to handle events and one to handle processing, and configures the web worker to print a message to the console during initialization.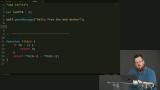 Kyle creates two-way communication between the web worker and the web page and explains how the structured clone algorithm determines how the data is sent.
Kyle creates two-way communication between the web worker and the web page and explains how the structured clone algorithm determines how the data is sent.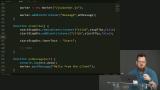 Kyle gives a history of how the problem of web workers copying transferred data has been dealt with, mentioning transferables, shared array buffers, and the atomics API.
Kyle gives a history of how the problem of web workers copying transferred data has been dealt with, mentioning transferables, shared array buffers, and the atomics API. Kyle configures the web worker to do the processing work of getting Fibonacci numbers when a message is received, and the client to update the web page to display the new number.
Kyle configures the web worker to do the processing work of getting Fibonacci numbers when a message is received, and the client to update the web page to display the new number. Kyle fields questions about browser choice and debugging web workers in the developer tools console.
Kyle fields questions about browser choice and debugging web workers in the developer tools console.
Service Workers
Section Duration: 26 minutes
 Kyle explains what the job of a service worker is, describing service worker code as a proxy that exists in the browser. The common use case of caching is discussed.
Kyle explains what the job of a service worker is, describing service worker code as a proxy that exists in the browser. The common use case of caching is discussed. Kyle and the students brainstorm ideas for use cases involving service workers. Among those mentioned are transparent URL rewriting, programmatically-created content, prefetching, and dependency injection.
Kyle and the students brainstorm ideas for use cases involving service workers. Among those mentioned are transparent URL rewriting, programmatically-created content, prefetching, and dependency injection. Kyle analyzes misconceptions around the well-known technology of push notifications, including the incorrect perception that it is a single technology as opposed to being two.
Kyle analyzes misconceptions around the well-known technology of push notifications, including the incorrect perception that it is a single technology as opposed to being two. Kyle highlights the a website resource for help in building service workers that contains side-by-side, annotated code examples for performing operations involving service workers.
Kyle highlights the a website resource for help in building service workers that contains side-by-side, annotated code examples for performing operations involving service workers.
Service Worker Project
Section Duration: 1 hour, 13 minutes
 Kyle outlines an optional process for following along with the course using commit hashes.
Kyle outlines an optional process for following along with the course using commit hashes. Kyle introduces the project on service workers, which is to take a blog website which has been provided and add a service worker to prevent site death during offline and server downtimes.
Kyle introduces the project on service workers, which is to take a blog website which has been provided and add a service worker to prevent site death during offline and server downtimes.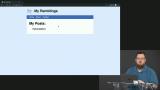 Kyle demonstrates how to detect a user's offline status and show a visual indication of the detected status by toggling the visibility of an offline icon.
Kyle demonstrates how to detect a user's offline status and show a visual indication of the detected status by toggling the visibility of an offline icon.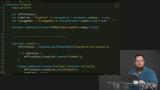 Kyle writes an asynchronous function to initialize a service worker by installing and registering it.
Kyle writes an asynchronous function to initialize a service worker by installing and registering it.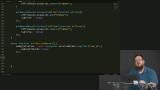 Kyle writes code to enable access to a service worker based on three possible states: installing, waiting, or active.
Kyle writes code to enable access to a service worker based on three possible states: installing, waiting, or active. Kyle begins to write the code for the service worker by adding a version number, a main function, and event handlers for install and activation events.
Kyle begins to write the code for the service worker by adding a version number, a main function, and event handlers for install and activation events.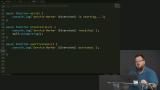 Kyle introduces the waitUntil method, a way to tell the browser not to shut down, and gives an example of a situation where allowing the service worker to continue to run is useful.
Kyle introduces the waitUntil method, a way to tell the browser not to shut down, and gives an example of a situation where allowing the service worker to continue to run is useful. After demonstrating how to use the developer console to inspect service workers, Kyle analyzes the lifecycle of a service worker by pointing out the phases passed through during creation, stopping, and starting.
After demonstrating how to use the developer console to inspect service workers, Kyle analyzes the lifecycle of a service worker by pointing out the phases passed through during creation, stopping, and starting. Kyle adds the ability to communicate with the service worker from the client by creating a function to send a status message through a channel port the service worker is listening on.
Kyle adds the ability to communicate with the service worker from the client by creating a function to send a status message through a channel port the service worker is listening on. Kyle hooks up the other end of communication between the service worker and the client. The client and service worker are then able to communicate about logged in and online status.
Kyle hooks up the other end of communication between the service worker and the client. The client and service worker are then able to communicate about logged in and online status.
Service Worker Cache
Section Duration: 34 minutes
 Kyle creates a version cache name for the collection in the cache, discusses loading and updating resource data about the cache and caching for logged in versus logged out users, and creates a list of URLs to be cached.
Kyle creates a version cache name for the collection in the cache, discusses loading and updating resource data about the cache and caching for logged in versus logged out users, and creates a list of URLs to be cached. Kyle fields questions about request URLs and friendly URL rewriting in relation to caching.
Kyle fields questions about request URLs and friendly URL rewriting in relation to caching. Kyle writes an asynchronous function to cache using the URLs specified in the list, mapping over the array of files and either getting a result from the cache or making a fetch request to add to the cache.
Kyle writes an asynchronous function to cache using the URLs specified in the list, mapping over the array of files and either getting a result from the cache or making a fetch request to add to the cache. Kyle adds function calls for caching logged out files on application startup and service worker activation, differentiating between when and when not to forcibly reload the cache. Cached items are then viewed from the developer console.
Kyle adds function calls for caching logged out files on application startup and service worker activation, differentiating between when and when not to forcibly reload the cache. Cached items are then viewed from the developer console. Kyle creates a method to clear the service worker cache by removing the old items, waiting for all delete operations to finish, and creating a new cache with the updated version name. Questions are then answered about cache expiration.
Kyle creates a method to clear the service worker cache by removing the old items, waiting for all delete operations to finish, and creating a new cache with the updated version name. Questions are then answered about cache expiration.
Service Worker Routing
Section Duration: 55 minutes
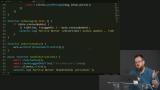 Kyle makes a recommendation about when to add a service worker to a project. Then, code is written to intercept inbound requests coming from the page through the service worker.
Kyle makes a recommendation about when to add a service worker to a project. Then, code is written to intercept inbound requests coming from the page through the service worker.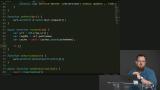 Kyle discusses strategies for responding to requests, including loading from the server based on online status, using the cache, caching proactively, and checking the cache before loading from the server.
Kyle discusses strategies for responding to requests, including loading from the server based on online status, using the cache, caching proactively, and checking the cache before loading from the server.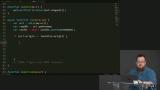 Kyle implements a strategy for responding to inbound and outbound requests, which is to make the request to the server and then cache the resource if it is not already present in the cache.
Kyle implements a strategy for responding to inbound and outbound requests, which is to make the request to the server and then cache the resource if it is not already present in the cache.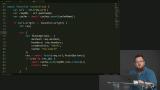 Kyle tests the application's ability to run offline using the cache, enabling the user to view site pages offline, even when the server is shut off.
Kyle tests the application's ability to run offline using the cache, enabling the user to view site pages offline, even when the server is shut off. Kyle fields questions about page reloads while in offline mode and dealing with request URLs with query parameters compared to ones without.
Kyle fields questions about page reloads while in offline mode and dealing with request URLs with query parameters compared to ones without. Kyle walks through additional logic for the router that handles specific cases, dealing with the routing behavior that is not sensitive to whether the user is logged in.
Kyle walks through additional logic for the router that handles specific cases, dealing with the routing behavior that is not sensitive to whether the user is logged in. Kyle pulls in another update to the router logic dealing with specific routing cases having to do with behavior sensitive to logged in users. A refactor is applied to the logged out routing code.
Kyle pulls in another update to the router logic dealing with specific routing cases having to do with behavior sensitive to logged in users. A refactor is applied to the logged out routing code. Kyle discusses routing behaviors for authenticated users visiting login and logout pages. Explanation is given for why the behavior of cache routing is designed to mimic the server.
Kyle discusses routing behaviors for authenticated users visiting login and logout pages. Explanation is given for why the behavior of cache routing is designed to mimic the server. Kyle demos the application's behavior for authentication aware routing, including showing the cached API request, viewing the cached add post page, and viewing cached blog posts.
Kyle demos the application's behavior for authentication aware routing, including showing the cached API request, viewing the cached add post page, and viewing cached blog posts.
Improving UX
Section Duration: 10 minutes
 Kyle explains how to slowly load posts in the background by caching all posts by ID during the service worker's initialization.
Kyle explains how to slowly load posts in the background by caching all posts by ID during the service worker's initialization.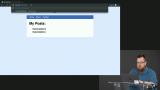 Kyle demonstrates how the application can help the user by using IndexDB to enable offline saving for data on the add post page without an internet connection.
Kyle demonstrates how the application can help the user by using IndexDB to enable offline saving for data on the add post page without an internet connection.
Wrapping Up
Section Duration: 1 minute
 Kyle concludes the course by looking back to where the application started, summarizing what was done, and emphasizing the exciting future of a web that includes service workers.
Kyle concludes the course by looking back to where the application started, summarizing what was done, and emphasizing the exciting future of a web that includes service workers.