Temporal
Open Source AI with Python & Hugging Face

4 hours, 33 minutes
CC

Course Description
Build your own AI workflows beyond Anthropic and OpenAI using open-source tools. Use Hugging Face for text tasks like classification, summarization, and Q&A, and learn how transformers and attention power these models. Fine-tune with LoRA for custom behavior, then generate and adapt images with Stable Diffusion and DreamBooth. Gain the skills to create custom AI solutions!
Prerequisite: Practical Prompt Engineering or equivalent programming experience. Familiarity with basic ML concepts helps.
Preview
Course Details
Published: August 22, 2025
Rating
Learning Paths
Learn Straight from the Experts Who Shape the Modern Web
Your Path to Senior Developer and Beyond
- 250+ In-depth courses
- 24 Learning Paths
- Industry Leading Experts
- Live Interactive Workshops
Table of Contents
Introduction
Section Duration: 9 minutes
 Steve introduces the course content, including AI fundamentals such as text transformations, fine-tuning GPT models, and image generation in Python. The course takes a two-pass approach with clear explanations and hands-on demos to make complex concepts both accessible and practical.
Steve introduces the course content, including AI fundamentals such as text transformations, fine-tuning GPT models, and image generation in Python. The course takes a two-pass approach with clear explanations and hands-on demos to make complex concepts both accessible and practical. Steve discusses course tools including Google Colab notebooks and Hugging Face for the session. Participants will need a Google account for Colab. Hugging Face is like GitHub for open-source models and datasets, simplifying model access and usage.
Steve discusses course tools including Google Colab notebooks and Hugging Face for the session. Participants will need a Google account for Colab. Hugging Face is like GitHub for open-source models and datasets, simplifying model access and usage.
Pipeline Basics
Section Duration: 1 hour, 29 minutes
 Steve explores text processing beyond Q&A, focusing on practical applications like sentiment analysis and text generation. He covers nuances such as sarcasm detection, model parameters like temperature, and encourages experimenting with different techniques for creative results.
Steve explores text processing beyond Q&A, focusing on practical applications like sentiment analysis and text generation. He covers nuances such as sarcasm detection, model parameters like temperature, and encourages experimenting with different techniques for creative results. Steve discusses various applications of machine learning and AI, such as zero-shot classification for categorizing text, fill mask for predicting the next word in a sentence, sentiment analysis, summarization, and named entity recognition for identifying entities like people, places, and organizations in text.
Steve discusses various applications of machine learning and AI, such as zero-shot classification for categorizing text, fill mask for predicting the next word in a sentence, sentiment analysis, summarization, and named entity recognition for identifying entities like people, places, and organizations in text. Steve walks through using Google Colab notebooks for working with Hugging Face tokens and models. He explains how to access tokens, create new tokens, and set up the environment for running code in the notebooks. Steve also touches on runtime options, running code blocks, and managing sessions in Google Colab.
Steve walks through using Google Colab notebooks for working with Hugging Face tokens and models. He explains how to access tokens, create new tokens, and set up the environment for running code in the notebooks. Steve also touches on runtime options, running code blocks, and managing sessions in Google Colab.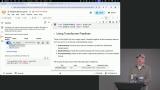 Steve discusses accessing libraries like transformers, which simplify tasks like text generation and sentiment analysis by abstracting tokenization, embeddings, and model processing. He also demonstrates sentiment analysis using a pipeline function that determines if a statement is positive or negative.
Steve discusses accessing libraries like transformers, which simplify tasks like text generation and sentiment analysis by abstracting tokenization, embeddings, and model processing. He also demonstrates sentiment analysis using a pipeline function that determines if a statement is positive or negative.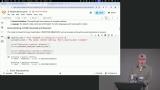 Steve discusses the contents of models from Hugging Face, which consist of tensors, weights, and numbers representing text. Models like GPT-2 use text generation based on previous words to predict the next word or punctuation. Parameters like temperature can be adjusted to control the creativity of generated text.
Steve discusses the contents of models from Hugging Face, which consist of tensors, weights, and numbers representing text. Models like GPT-2 use text generation based on previous words to predict the next word or punctuation. Parameters like temperature can be adjusted to control the creativity of generated text.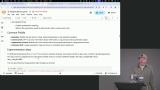 Steve explains the concept of zero-shot classification, where a model can classify text into categories it hasn't been trained on. He demonstrates how to use this technique interactively, allowing for experimentation with different strings and categories. Steve also discusses the differences between question answering and text generation, highlighting the contextual nature of question answering models.
Steve explains the concept of zero-shot classification, where a model can classify text into categories it hasn't been trained on. He demonstrates how to use this technique interactively, allowing for experimentation with different strings and categories. Steve also discusses the differences between question answering and text generation, highlighting the contextual nature of question answering models. Steve explains question-and-answer models, highlighting their extractive approach vs generative systems like ChatGPT. He also mentions the role of context size in producing accurate answers and factors such as confidence scores and filtering out low-confidence results.
Steve explains question-and-answer models, highlighting their extractive approach vs generative systems like ChatGPT. He also mentions the role of context size in producing accurate answers and factors such as confidence scores and filtering out low-confidence results. Steve discusses the differences between models like GPT and BERT, with BERT focusing on bidirectional context. He demonstrates how BERT's fill mask function predicts missing words based on surrounding context.
Steve discusses the differences between models like GPT and BERT, with BERT focusing on bidirectional context. He demonstrates how BERT's fill mask function predicts missing words based on surrounding context. Steve explains that summarization is limited by factors like model size, rollout stages, and progressive enhancement constraints, while NER can identify and label entities such as people, places, and organizations from unstructured text, making it valuable for structuring data.
Steve explains that summarization is limited by factors like model size, rollout stages, and progressive enhancement constraints, while NER can identify and label entities such as people, places, and organizations from unstructured text, making it valuable for structuring data.
Tokenization
Section Duration: 34 minutes
 Steve discusses the concepts of tokenization, encoding, and decoding in the context of AI models. Tokenization involves breaking down text into smaller units, converting them into numeric representations, and analyzing their relationships in multi-dimensional space. Encoding translates tokens into numbers, while decoding reverses this process to reconstruct the original text.
Steve discusses the concepts of tokenization, encoding, and decoding in the context of AI models. Tokenization involves breaking down text into smaller units, converting them into numeric representations, and analyzing their relationships in multi-dimensional space. Encoding translates tokens into numbers, while decoding reverses this process to reconstruct the original text. Steve discusses how neural networks require input sequences to be the same length, which is achieved by padding shorter strings with special tokens. Attention masks are used to mark real content with ones and padding with zeros, allowing the model to ignore the filler when processing, which enables batching and accurate comparison between sequences in tasks.
Steve discusses how neural networks require input sequences to be the same length, which is achieved by padding shorter strings with special tokens. Attention masks are used to mark real content with ones and padding with zeros, allowing the model to ignore the filler when processing, which enables batching and accurate comparison between sequences in tasks. Steve explores tokenization using different models like BERT, GPT2, RoBERTa, and T5, showcasing how each tokenizer breaks down text into tokens differently. He also discusses the process of encoding and decoding text, highlighting the uniqueness of each model's. tokenization approach
Steve explores tokenization using different models like BERT, GPT2, RoBERTa, and T5, showcasing how each tokenizer breaks down text into tokens differently. He also discusses the process of encoding and decoding text, highlighting the uniqueness of each model's. tokenization approach Steve discusses the process of tokenizing and vectorizing text data using PyTorch, including the concepts of padding, truncation, token IDs, attention masks, and vocabulary mapping. He also discusses the model's role in translating text and the structure of vocabulary mapping in tokenization.
Steve discusses the process of tokenizing and vectorizing text data using PyTorch, including the concepts of padding, truncation, token IDs, attention masks, and vocabulary mapping. He also discusses the model's role in translating text and the structure of vocabulary mapping in tokenization.
Transformers
Section Duration: 51 minutes
 Steve explains how transformers work, including the core components: embeddings, transform blocks, and output probabilities. He also discusses how self-attention allows tokens to consider surrounding words to refine their meaning in context, such as distinguishing between "river bank" and "savings bank."
Steve explains how transformers work, including the core components: embeddings, transform blocks, and output probabilities. He also discusses how self-attention allows tokens to consider surrounding words to refine their meaning in context, such as distinguishing between "river bank" and "savings bank." Steve answers students’ questions about how token IDs work, the difference between fine-tuning and inference, how models handle memory, and how tools like vector databases can provide external context, such as a code base, without retraining the model.
Steve answers students’ questions about how token IDs work, the difference between fine-tuning and inference, how models handle memory, and how tools like vector databases can provide external context, such as a code base, without retraining the model. Steve discusses using vector databases to augment prompts for models like ChatGPT or Claude, the process of tokenization, embedding, and finding relevant content to enhance queries. He also demonstrates visualizing semantic relationships between words using BERTviz.
Steve discusses using vector databases to augment prompts for models like ChatGPT or Claude, the process of tokenization, embedding, and finding relevant content to enhance queries. He also demonstrates visualizing semantic relationships between words using BERTviz. Steve explains encoders and decoders in neural networks, where encoders convert words into numerical vectors, while decoders reconstruct words from these vectors to form sentences. He also discusses decoding strategies like Top-K and Top-p sampling to predict the next word in a sequence based on confidence levels.
Steve explains encoders and decoders in neural networks, where encoders convert words into numerical vectors, while decoders reconstruct words from these vectors to form sentences. He also discusses decoding strategies like Top-K and Top-p sampling to predict the next word in a sequence based on confidence levels. Steve discusses decoding strategies, such as greedy decoding and temperature adjustments, demonstrating how these impact the model's output creativity. He also touches on the importance of end-of-sequence tokens to control model output length and the distinction between generative and extractive text generation approaches.
Steve discusses decoding strategies, such as greedy decoding and temperature adjustments, demonstrating how these impact the model's output creativity. He also touches on the importance of end-of-sequence tokens to control model output length and the distinction between generative and extractive text generation approaches.
Fine-Tuning
Section Duration: 28 minutes
 Steve discusses fine-tuning in models, the trade-offs between adding more content through data augmentation and changing the output style through fine-tuning. He also explains fine-tuning as building upon an existing model's knowledge rather than starting from scratch.
Steve discusses fine-tuning in models, the trade-offs between adding more content through data augmentation and changing the output style through fine-tuning. He also explains fine-tuning as building upon an existing model's knowledge rather than starting from scratch. Steve explains the concept of low-rank adaptation, where only a small subset of extra layers are added and tuned on top of a model to achieve significant results with minimal effort. This approach allows for easy customization and adaptation of models for specific tasks without the need to store entirely new models, acting as plug-ins to enhance functionality.
Steve explains the concept of low-rank adaptation, where only a small subset of extra layers are added and tuned on top of a model to achieve significant results with minimal effort. This approach allows for easy customization and adaptation of models for specific tasks without the need to store entirely new models, acting as plug-ins to enhance functionality. Steve discusses fine-tuning a model, specifically focusing on preparing a dataset of quotes for training. He emphasizes the importance of selecting a GPU runtime and provides insights into data preparation, model quantization, and utilizing a pre-trained model like GPT-2 medium. Steve also mentions strategies to optimize memory usage, such as quantization, to stay within the free tier limits.
Steve discusses fine-tuning a model, specifically focusing on preparing a dataset of quotes for training. He emphasizes the importance of selecting a GPU runtime and provides insights into data preparation, model quantization, and utilizing a pre-trained model like GPT-2 medium. Steve also mentions strategies to optimize memory usage, such as quantization, to stay within the free tier limits. Steve demonstrates of fine-tuning a language model using a library from Hugging Face with 355 million parameters. He walks through tokenization, training loops, and the impact of fine-tuning on model behavior, showcasing how a small dataset and quick training can significantly alter model outputs.
Steve demonstrates of fine-tuning a language model using a library from Hugging Face with 355 million parameters. He walks through tokenization, training loops, and the impact of fine-tuning on model behavior, showcasing how a small dataset and quick training can significantly alter model outputs.
Image Generation
Section Duration: 55 minutes
 Steve discusses stable diffusion, which transforms chaotic noise into recognizable images like cats or hippos. The process involves iteratively refining random noise towards a desired image. Various parameters such as num_inference_steps, GPU capacity, and guidance_scale influence the quality and speed of image generation.
Steve discusses stable diffusion, which transforms chaotic noise into recognizable images like cats or hippos. The process involves iteratively refining random noise towards a desired image. Various parameters such as num_inference_steps, GPU capacity, and guidance_scale influence the quality and speed of image generation. Steve discusses the impact of prompt quality including negative prompts in the image generation process and explores different options like attention slicing for balancing quality and speed.
Steve discusses the impact of prompt quality including negative prompts in the image generation process and explores different options like attention slicing for balancing quality and speed. Steve demonstrates text-to-image generation, model selection, and fine-tuning prompts to achieve desired outputs. He also discusses the importance of exploring different models, adjusting parameters, and understanding the nuances of generating images using diffusion models on GPUs.
Steve demonstrates text-to-image generation, model selection, and fine-tuning prompts to achieve desired outputs. He also discusses the importance of exploring different models, adjusting parameters, and understanding the nuances of generating images using diffusion models on GPUs. Steve demonstrates image-to-image transformation, which involves using an image as a baseline to further adjust it. By combining text-to-image and image-to-image pipelines, adjustments can be made to images based on different strengths, affecting the level of transformation.
Steve demonstrates image-to-image transformation, which involves using an image as a baseline to further adjust it. By combining text-to-image and image-to-image pipelines, adjustments can be made to images based on different strengths, affecting the level of transformation.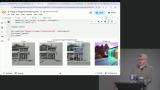 Steve demonstrates utilizing DreamBooth to fine-tune stable diffusion models in a lightweight way, focusing on subject matter rather than style. By training the model with a few images of a made-up term, users can effectively teach the model to associate that term with specific images.
Steve demonstrates utilizing DreamBooth to fine-tune stable diffusion models in a lightweight way, focusing on subject matter rather than style. By training the model with a few images of a made-up term, users can effectively teach the model to associate that term with specific images.
Wrapping Up
Section Duration: 3 minutes
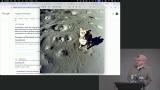 Steve wraps up the course by mentioning the creative potential in utilizing AI, the ease of fine-tuning models, and accessing resources like GPUs. He also encourages students to think beyond pre-trained models, referencing the course's previous example of fine-tuning a smaller model with limited data for significant improvements.
Steve wraps up the course by mentioning the creative potential in utilizing AI, the ease of fine-tuning models, and accessing resources like GPUs. He also encourages students to think beyond pre-trained models, referencing the course's previous example of fine-tuning a smaller model with limited data for significant improvements.