Netflix
AI Agent: From Prototype to Production

3 hours, 50 minutes
CC

Course Description
Build production-ready AI apps. Write evals to measure LLM and tool accuracy. Implement a Retrieval Augmented Generation (RAG) pipeline and explore how structured outputs provide a predictable schema for LLM responses. Responsibly manage costs and token limits with proper context memory management. Build better guardrails within the system with human-in-the-loop best practices.
This course and others like it are available as part of our Frontend Masters video subscription.
Preview
Course Details
Published: December 11, 2024
Rating
Learning Paths
Learn Straight from the Experts Who Shape the Modern Web
Your Path to Senior Developer and Beyond
- 250+ In-depth courses
- 24 Learning Paths
- Industry Leading Experts
- Live Interactive Workshops
Table of Contents
Introduction
Section Duration: 11 minutes
 Scott Moss begins the course with an overview of the prerequisites and tooling required to code, along with examples. This course builds on Frontend Masters' "Building an AI Agent from Scratch" course and will focus on preparing an agent for production.
Scott Moss begins the course with an overview of the prerequisites and tooling required to code, along with examples. This course builds on Frontend Masters' "Building an AI Agent from Scratch" course and will focus on preparing an agent for production. Scott spends a few minutes reviewing LLMs and AI agents. LLMs can process text by analyzing relationships between the different parts or tokens of the input. Agents are a more sophisticated system that uses an LLM as its "brain" but enhances it with memory, tool use, decision-making abilities, and the capacity to take action in the real world.
Scott spends a few minutes reviewing LLMs and AI agents. LLMs can process text by analyzing relationships between the different parts or tokens of the input. Agents are a more sophisticated system that uses an LLM as its "brain" but enhances it with memory, tool use, decision-making abilities, and the capacity to take action in the real world.
Improving LLMs with Evals
Section Duration: 1 hour, 10 minutes
 Scott introduces evals that test and score responses from LLMs and agents. Datasets are required to help an eval understand the quality of a response. Datasets can be curated or provided by users who continuously rank responses they receive from an agent. This measuring is an essential component of production agents to ensure high levels of quality.
Scott introduces evals that test and score responses from LLMs and agents. Datasets are required to help an eval understand the quality of a response. Datasets can be curated or provided by users who continuously rank responses they receive from an agent. This measuring is an essential component of production agents to ensure high levels of quality. Scott discusses what evals should measure. Quality metrics can help assess how well tasks are performed. Measuring also adds safety and reliability to the application by ensuring the system operates within acceptable bounds.
Scott discusses what evals should measure. Quality metrics can help assess how well tasks are performed. Measuring also adds safety and reliability to the application by ensuring the system operates within acceptable bounds. Scott walks through the eval framework created for this course. A scorer is created to determine whether the system's output is what was expected given the input. A question about storing inputs, outputs, and expected results for later analysis is also addressed in this lesson.
Scott walks through the eval framework created for this course. A scorer is created to determine whether the system's output is what was expected given the input. A question about storing inputs, outputs, and expected results for later analysis is also addressed in this lesson.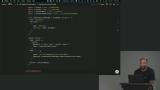 Scott codes an eval for the Reddit tool. The eval's task calls the runLLM method with the input. Since the word "reddit" is contained in the input, eval is expected to call the Reddit tool.
Scott codes an eval for the Reddit tool. The eval's task calls the runLLM method with the input. Since the word "reddit" is contained in the input, eval is expected to call the Reddit tool. Scott demonstrates the React dashboard application included in the project. The dashboard displays the results from each eval run. The data for the dashboard is pulled from the results.json file in the project's root.
Scott demonstrates the React dashboard application included in the project. The dashboard displays the results from each eval run. The data for the dashboard is pulled from the results.json file in the project's root.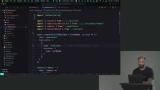 Scott creates two more evals. One measures the dadJokes tool, and the other measures the generateImage tool. Since users may refer to an image as a "photo", the prompt is updated to help the system handle both scenarios. This demonstrates the interactive process of better accuracy.
Scott creates two more evals. One measures the dadJokes tool, and the other measures the generateImage tool. Since users may refer to an image as a "photo", the prompt is updated to help the system handle both scenarios. This demonstrates the interactive process of better accuracy. Scott creates an eval to test all the tools. The eval is populated with several data items and run. Depending on the score, modifications to the prompt may be required to achieve a 100% success rate. After creating the eval, some additional metric tools are discussed.
Scott creates an eval to test all the tools. The eval is populated with several data items and run. Depending on the score, modifications to the prompt may be required to achieve a 100% success rate. After creating the eval, some additional metric tools are discussed.
Retrieval Augmented Generation (RAG)
Section Duration: 1 hour, 7 minutes
 Scott introduces RAG, or Retrieval Augmented Generation, which is a shift in how to approach LLM knowledge enhancement. Rather than relying on an LLM's built-in knowledge, RAG dynamically injects relevant information into the conversation by retrieving it from an external knowledge base.
Scott introduces RAG, or Retrieval Augmented Generation, which is a shift in how to approach LLM knowledge enhancement. Rather than relying on an LLM's built-in knowledge, RAG dynamically injects relevant information into the conversation by retrieving it from an external knowledge base. Scott walks through the RAG pipeline to highlight the core components and how they work together. The pipeline includes document processing, embedding generation, and storage/indexing. Once the query is received, the retrieval process can begin.
Scott walks through the RAG pipeline to highlight the core components and how they work together. The pipeline includes document processing, embedding generation, and storage/indexing. Once the query is received, the retrieval process can begin. Scott introduces Upstash which is where the movie data is stored and indexed. Upstash is a vector database that allows for querying and filtering. Results are returned based on their proximity or correctness.
Scott introduces Upstash which is where the movie data is stored and indexed. Upstash is a vector database that allows for querying and filtering. Results are returned based on their proximity or correctness. Scott codes a script to ingest the data in the Upstash. Once the script is complete, the data can be queried in Upstash with a movieSearch tool.
Scott codes a script to ingest the data in the Upstash. Once the script is complete, the data can be queried in Upstash with a movieSearch tool. Scott creates a query for searching the movies. For now, the query doesn't support filtering. The vector store will be sent the query and topK to return to the application.
Scott creates a query for searching the movies. For now, the query doesn't support filtering. The vector store will be sent the query and topK to return to the application. Scott creates the movieSearch tool for executing the search of the movie vector database. Scott tests the system by asking for a specific movie and later asking for a movie poster. The system correctly uses the moveSearch tool to return results and the generateImage tool for the poster. The final code can be found on the `step/4` branch in the repo.
Scott creates the movieSearch tool for executing the search of the movie vector database. Scott tests the system by asking for a specific movie and later asking for a movie poster. The system correctly uses the moveSearch tool to return results and the generateImage tool for the poster. The final code can be found on the `step/4` branch in the repo.
Structured Output
Section Duration: 16 minutes
 Scott introduces structured outputs, which represent a significant advancement in handling AI responses. They ensure that LLM responses always adhere to a predefined JSON Schema, eliminating many common issues with free-form AI outputs.
Scott introduces structured outputs, which represent a significant advancement in handling AI responses. They ensure that LLM responses always adhere to a predefined JSON Schema, eliminating many common issues with free-form AI outputs. Scott shares some limitations with structured outputs. One limitation is constraints on the schema, like the maximum number of objects or nesting levels. Another is string limitations, such as property length, size of the description, or JSON needing to be fully loaded before it can be parsed.
Scott shares some limitations with structured outputs. One limitation is constraints on the schema, like the maximum number of objects or nesting levels. Another is string limitations, such as property length, size of the description, or JSON needing to be fully loaded before it can be parsed.
Human in the Loop
Section Duration: 29 minutes
 Scott explains why Human in the Loop (HITL) is a critical safety pattern in AI systems where specific actions require explicit human approval before execution. Approvals can be synchronous, asynchronous, or tiered. Several factors for designing the approval flow are also discussed.
Scott explains why Human in the Loop (HITL) is a critical safety pattern in AI systems where specific actions require explicit human approval before execution. Approvals can be synchronous, asynchronous, or tiered. Several factors for designing the approval flow are also discussed.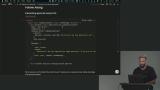 Scott adds a method to the LLM module to run the approval check. The method receives the model, temperature, schema for the response format, and an array of messages. The messages provide a system prompt instructing the LLM to determine if the user approved the request and follows that message with the user's response.
Scott adds a method to the LLM module to run the approval check. The method receives the model, temperature, schema for the response format, and an array of messages. The messages provide a system prompt instructing the LLM to determine if the user approved the request and follows that message with the user's response.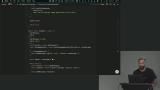 Scott updates the agent by adding the approval flow. A condition is added to check if the tool call is the generateImage tool. If so, the execution is stopped, and the user's approval is requested.
Scott updates the agent by adding the approval flow. A condition is added to check if the tool call is the generateImage tool. If so, the execution is stopped, and the user's approval is requested.
Memory Management
Section Duration: 28 minutes
 Scott explores strategies for history and memory management. The challenge of managing chat history in LLM applications is balancing maintaining context and managing token limits. Every token sent increases the cost and consumes context window space. Losing important context can severely impact the quality of responses.
Scott explores strategies for history and memory management. The challenge of managing chat history in LLM applications is balancing maintaining context and managing token limits. Every token sent increases the cost and consumes context window space. Losing important context can severely impact the quality of responses.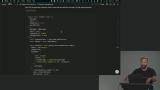 Scott implements summaries and a way to shorten the context size. Whenever the system has more than 10 messages, it will remove the oldest five messages and replace them with a summary of those messages.
Scott implements summaries and a way to shorten the context size. Whenever the system has more than 10 messages, it will remove the oldest five messages and replace them with a summary of those messages. Scott shares some resources for building a more robust evaluation pipeline and advanced RAG fine-tuning techniques. He also discusses some advances in generative UIs.
Scott shares some resources for building a more robust evaluation pipeline and advanced RAG fine-tuning techniques. He also discusses some advances in generative UIs.
Wrapping Up
Section Duration: 6 minutes
 Scott wraps up the course with some tips for further researching emerging AI techniques and discusses Vercel's AI SDK.
Scott wraps up the course with some tips for further researching emerging AI techniques and discusses Vercel's AI SDK.
Learn Straight from the Experts Who Shape the Modern Web
- 250+In-depth Courses
- Industry Leading Experts
- 24Learning Paths
- Live Interactive Workshops