The Hard Parts of JavaScript
Master closure, async, OOP, and metaprogramming

Why Take This Course?
Build a comprehensive mental model around concepts that even the most experienced developers often lack.
Higher-Order Functions & Closure
Master the patterns that let you build flexible, reusable functions instead of copy-pasting the same logic over and over
Asynchronous Code
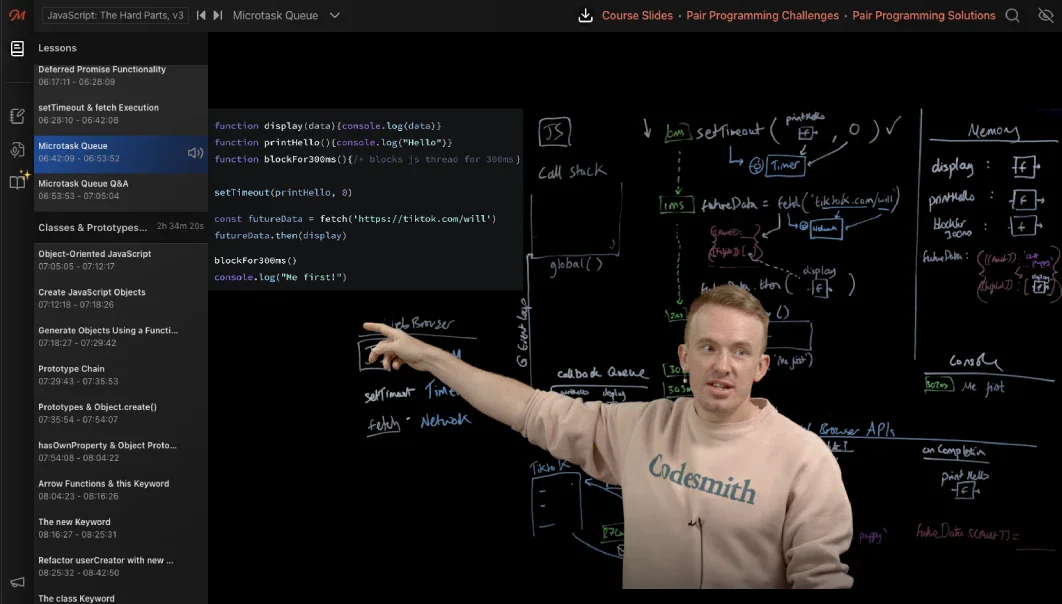
Go under the hood with Promises and follow the thread of execution through the call stack, callback queue, and microtask queue
Object-Oriented Programming Principles
Go beyond prototypical inheritance and explore modern, object-oriented JavaScript features like classes and static properties and methods
Type Coercion & Metaprogramming
Use Symbols and metaprogramming to understand the JavaScript type system and create type coercion operations
What You'll Learn
Build Foundational Knowledge and Strong Technical Communication Skills
54
Lessons
9.7
Hours
4.9
Rating
Simultaneously deepen your understanding of JavaScript most complex concepts while building the technical communications skills required for senior engineers and beyond.
- Follow JavaScript code line-by-line using the thread of execution, execution contexts, and the call stack to understand how functions are called
- Create higher-order functions and callbacks to write declarative, reusable code following the DRY principle
- Explore how closure works using a "backpack" metaphor of persistent memory that functions carry with them, enabling advanced patterns like memoization and iterators
- Use type coercion to automatically convert data types, and Symbol.toPrimitive to override the default language behavior
- Manage asynchronous operations using browser APIs, the callback queue, microtask queue, and the event loop despite being single-threaded
- Use the "new" keyword to automate object creation and prototype linking, and modern syntactic sugar like classes for cleaner, object-oriented code.

Will Sentance Codesmith Founder & Chief AI Officer
Your (Awesome) Instructor
Depth of knowledge is the ability to explain hard stuff to other people, because if you can explain it to somebody else, I think it's a good measure of whether you understand it yourself.
A Decade of Experience in Software Engineering Education
Helping thousands of learners develop deeper capacities, like rigorous problem solving and communication, that fuel long-term success in fast-changing fields.
Founder & Chief AI Officer
Driven to develop institutions & tools that help people put in hard work, get the support needed to persist through the challenges, and see it pay off with autonomy over their lives.
Visiting Fellow at the University of Oxford
Research focused on how emerging AI tools intersect with human learning and judgment.
Hard Parts Series
Provides a complete mental model and autonomy over the most complex concepts in JavaScript.
Prerequisite: JavaScript: From First Steps to Professional or a solid understanding of using JavaScript.
Introduction
8 minutes
Principles of JavaScript
20 minutes
Callbacks & Higher Order functions
1 hour, 17 minutes
Closure
1 hour, 19 minutes
Type Coercion & Metaprogramming
1 hour, 50 minutes
Asynchronous JavaScript & the event loop
2 hours, 8 minutes
Classes & Prototypes (OOP)
2 hours, 34 minutes
Wrapping Up
4 minutes
9 hours, 43 minutes
Best in Class Course Player
Your Learning Adventure Begins Here
- Course Progress: Learn at your own pace and pick up right where you left off.
- Robust Note-Taking: Take notes alongside transcripts to easily reference information while learning.
- Quizzes & Flashcards: Reinforce your learning with quizzes and flashcards after every lesson.

Earn a Completion Certificate
After completing this course, you'll receive a certificate of completion that serves as proof of your achievement, showcasing your expertise, and commitment to professional development. You can easily share this certificate on your LinkedIn profile to highlight your new skills and demonstrate continuous learning to potential employers and professional connections.
Get Started with JavaScript: The Hard Parts, v3 and Much More
- 250+ In-depth Courses
- 24 Learning Paths
- Industry Leading Experts
- Live Interactive Workshops
What They're Saying about Will Sentance
Elijah Manor

Austin Akers

Nitya Narasimhan, PhD

Kelvin Omereshone

Rita Iglesias Gandara

Loved by 500k+ developers
I cannot describe in words how great this course was. Will is such a great teacher that this was the first time since childhood that I wasn't happy a course had to end. It was a little hard at the end, but I loved it. It's so entertaining and interactive that I literally know every single attendee's name in the auditorium. ;) Thanks a lot. ;)

Touraj Shahparnia
Quality refresher with some well-chosen additions. Great work as always :)

Richard Washington