You Don't Know JS
Practical Problem Solving with Algorithms

9 hours, 14 minutes
CC

Course Description
You've likely taken several algorithms and data structures courses and know the "what", and now it's time to put the knowledge to practice! Develop better problem-solving skills by thinking through challenges and applying various algorithms and computer science techniques. Use recursion, traversals, acyclic paths, memoization, and garbage collection to optimize your solutions and think like a true algorithmist.
Preview
Course Details
Published: April 10, 2023
Rating
Learning Paths
Learn Straight from the Experts Who Shape the Modern Web
Your Path to Senior Developer and Beyond
- 250+ In-depth courses
- 24 Learning Paths
- Industry Leading Experts
- Live Interactive Workshops
Table of Contents
Introduction
Section Duration: 20 minutes
 Kyle Simpson begins the course by comparing the algorithms courses on Frontend Masters and shares a couple of recommended computer science books that outline data structures and algorithms.
Kyle Simpson begins the course by comparing the algorithms courses on Frontend Masters and shares a couple of recommended computer science books that outline data structures and algorithms. Kyle summarizes this course's key takeaways, including balancing CPU and Memory usage, shaping data structures to fit a problem, and understanding the drawbacks of premature optimization.
Kyle summarizes this course's key takeaways, including balancing CPU and Memory usage, shaping data structures to fit a problem, and understanding the drawbacks of premature optimization.
Primer
Section Duration: 36 minutes
 Kyle reviews common data structures found in computer science. These include Arrays, Stacks, Queues, Sets, Objects, Maps, Trees, and Graphs.
Kyle reviews common data structures found in computer science. These include Arrays, Stacks, Queues, Sets, Objects, Maps, Trees, and Graphs. Kyle reviews common algorithms found in computer science. These include BubbleSort, QuickSort, Tree Traversals, Path Finding, and Binary Search. Techniques like Iteration, Recursion, Indexing, and Referencing are also discussed in this lesson.
Kyle reviews common algorithms found in computer science. These include BubbleSort, QuickSort, Tree Traversals, Path Finding, and Binary Search. Techniques like Iteration, Recursion, Indexing, and Referencing are also discussed in this lesson. Kyle explains the Golden Weighted Ball problem, a common interview question. Eight identical balls are presented, and one of the eight balls is lighter. A scale must be used to determine which ball is the lightest in the fewest number of attempts.
Kyle explains the Golden Weighted Ball problem, a common interview question. Eight identical balls are presented, and one of the eight balls is lighter. A scale must be used to determine which ball is the lightest in the fewest number of attempts.
Example Problems
Section Duration: 22 minutes
 Kyle shares a few examples of problems that could be solved with algorithms. Problems include converting binary numbers to decimals, packing objects into the smallest container possible, and using collision detection to simplify UI markers.
Kyle shares a few examples of problems that could be solved with algorithms. Problems include converting binary numbers to decimals, packing objects into the smallest container possible, and using collision detection to simplify UI markers. Kyle continues sharing examples of problems that could be solved with algorithms. Creating a bot for automating Tetris games, analyzing puzzle pieces, and determining the largest contiguous object in a group are among the examples provided.
Kyle continues sharing examples of problems that could be solved with algorithms. Creating a bot for automating Tetris games, analyzing puzzle pieces, and determining the largest contiguous object in a group are among the examples provided.
Periodic Table Speller
Section Duration: 1 hour, 56 minutes
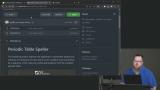 Kyle introduces the Periodic Table Speller project and provides instructions for cloning the project repository and running the code. In this project, a word entered in the text box will be spelled using element symbols from the periodic table. The "start-here" branch should be used to begin the project.
Kyle introduces the Periodic Table Speller project and provides instructions for cloning the project repository and running the code. In this project, a word entered in the text box will be spelled using element symbols from the periodic table. The "start-here" branch should be used to begin the project.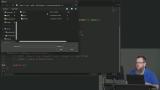 Kyle implements the lookup function, which returns an element based on a specified symbol. The toLowerCase method is used to make the lookup case-insensitive.
Kyle implements the lookup function, which returns an element based on a specified symbol. The toLowerCase method is used to make the lookup case-insensitive.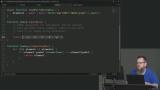 Kyle begins implementing the check function. It loops through the elements in the periodic table and checks to see if any symbols match part of the submitted word. If so, the check function is recursively called on for any remaining characters in the word.
Kyle begins implementing the check function. It loops through the elements in the periodic table and checks to see if any symbols match part of the submitted word. If so, the check function is recursively called on for any remaining characters in the word.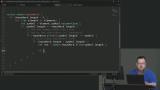 Kyle finishes the check function by adding base cases that stop the function from being recursively called. When a base case is reached, the recursive function calls are sequentially returned off the call stack, and the array of symbols is completed. The solution can be found on the option-1 branch.
Kyle finishes the check function by adding base cases that stop the function from being recursively called. When a base case is reached, the recursive function calls are sequentially returned off the call stack, and the array of symbols is completed. The solution can be found on the option-1 branch. Kyle optimizes the lookup function by creating an index of symbols when the data is loaded inside the loadPeriodicTable function. This index can be used inside the lookup function, eliminating the need for a loop. The option-1 branch can be used as a starting point for this lesson.
Kyle optimizes the lookup function by creating an index of symbols when the data is loaded inside the loadPeriodicTable function. This index can be used inside the lookup function, eliminating the need for a loop. The option-1 branch can be used as a starting point for this lesson. Kyle creates a findCandidates function to recursively find a list of symbol candidates matching one and two-letter character combinations in the submitted word. Note: Better code optimizations can be found on the option-2b and option-3 branches.
Kyle creates a findCandidates function to recursively find a list of symbol candidates matching one and two-letter character combinations in the submitted word. Note: Better code optimizations can be found on the option-2b and option-3 branches. Kyle refactors the check function to use a spellWords function that recursively searches for matching symbols by prioritizing two-character matches. Note: Better code optimizations can be found on the option-2b and option-3 branches.
Kyle refactors the check function to use a spellWords function that recursively searches for matching symbols by prioritizing two-character matches. Note: Better code optimizations can be found on the option-2b and option-3 branches. Kyle answers optimization questions and discusses alternate implementations. A small refactor is performed for consistency, and a bug is addressed. Note: Better code optimizations can be found on the option-2b and option-3 branches.
Kyle answers optimization questions and discusses alternate implementations. A small refactor is performed for consistency, and a bug is addressed. Note: Better code optimizations can be found on the option-2b and option-3 branches. Kyle highlights the performance characteristics of the Periodic Table Speller and compares theoretical vs. practical performance. Note: Better code optimizations can be found on the option-2b and option-3 branches.
Kyle highlights the performance characteristics of the Periodic Table Speller and compares theoretical vs. practical performance. Note: Better code optimizations can be found on the option-2b and option-3 branches.
Chessboard Diagonals
Section Duration: 1 hour, 29 minutes
 Kyle begins the Chessboard Diagonals project by writing a script that populates the webpage with a black and white chessboard. The board consists of eight rows and eight columns. DIV elements are used to represent each tile.
Kyle begins the Chessboard Diagonals project by writing a script that populates the webpage with a black and white chessboard. The board consists of eight rows and eight columns. DIV elements are used to represent each tile. Kyle demonstrates how the querySelectorAll method can be used to traverse the tiles on the chessboard. The querySelectorAll method returns a NodeList of elements matching the supplied pattern. A loop goes through the list of elements and removes the "highlighted" class from each element.
Kyle demonstrates how the querySelectorAll method can be used to traverse the tiles on the chessboard. The querySelectorAll method returns a NodeList of elements matching the supplied pattern. A loop goes through the list of elements and removes the "highlighted" class from each element. Kyle uses a series of for loops to search for diagonal tiles to highlight. Each loop traverses tiles in a different diagonal direction until an upper or lower bound is reached.
Kyle uses a series of for loops to search for diagonal tiles to highlight. Each loop traverses tiles in a different diagonal direction until an upper or lower bound is reached. Kyle optimizes the diagonal tile algorithm by reducing DOM traversals and saving a tile's row and column indices to dataset properties. Use the option-1 branch linked below as a starting point for this lesson.
Kyle optimizes the diagonal tile algorithm by reducing DOM traversals and saving a tile's row and column indices to dataset properties. Use the option-1 branch linked below as a starting point for this lesson. Kyle constructs a two-dimensional array to save references for each tile. Traversing and accessing the array is more performant than re-querying the DOM. Use the option-2 branch linked below as a starting point for this lesson.
Kyle constructs a two-dimensional array to save references for each tile. Traversing and accessing the array is more performant than re-querying the DOM. Use the option-2 branch linked below as a starting point for this lesson. Kyle rethinks the current data structure and explains why using a diagonal data structure can optimize the algorithm. Use the option-3 branch linked below as a starting point for this lesson.
Kyle rethinks the current data structure and explains why using a diagonal data structure can optimize the algorithm. Use the option-3 branch linked below as a starting point for this lesson. Kyle refactors the highlight function to utilize the diagonal data structure. A Map variable is used to create references to store major and minor diagonal indices for each element. The final solution for the Chessboard Diagonals problem can be found on the option-4 branch.
Kyle refactors the highlight function to utilize the diagonal data structure. A Map variable is used to create references to store major and minor diagonal indices for each element. The final solution for the Chessboard Diagonals problem can be found on the option-4 branch.
Knight's Dialer
Section Duration: 2 hours, 10 minutes
 Kyle introduces the Knight's Dialer exercise. Algorithms will be written to count the number of distinct paths that can be traversed when starting from a specific key and which different paths can be taken without landing on any previously visited keys.
Kyle introduces the Knight's Dialer exercise. Algorithms will be written to count the number of distinct paths that can be traversed when starting from a specific key and which different paths can be taken without landing on any previously visited keys. Kyle implements the reachableKeys function, which builds an array of nearby keys for each key on the dialer pad.
Kyle implements the reachableKeys function, which builds an array of nearby keys for each key on the dialer pad. Kyle refactors the code to replace the reachable keys algorithm with a static data structure. The reachable keys on the dial pad never change, so using a static data structure with the available values optimizes the overall application and eliminates the need to traverse the dialer when establishing the hops a knight can make.
Kyle refactors the code to replace the reachable keys algorithm with a static data structure. The reachable keys on the dial pad never change, so using a static data structure with the available values optimizes the overall application and eliminates the need to traverse the dialer when establishing the hops a knight can make.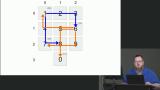 Kyle explains breadth-first search and implements the countPaths function, which is recursively called to determine the number of paths required to complete the specified hops.
Kyle explains breadth-first search and implements the countPaths function, which is recursively called to determine the number of paths required to complete the specified hops.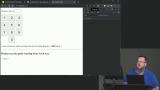 Kyle introduces big O complexity and how it affects the performance of an algorithm. The current implementation of the Knight's Dialer code has a complexity of 2.222 to the N.
Kyle introduces big O complexity and how it affects the performance of an algorithm. The current implementation of the Knight's Dialer code has a complexity of 2.222 to the N.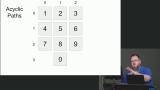 Kyle implements the listAcyclicPaths function. It returns an array of distinct paths with no repeated hops. A followPath function is also created to recursively follow each hop and push it into the paths array if it doesn't exist.
Kyle implements the listAcyclicPaths function. It returns an array of distinct paths with no repeated hops. A followPath function is also created to recursively follow each hop and push it into the paths array if it doesn't exist. Kyle explains how algorithms can be optimized by using memoization. When a path is followed, it can be saved using a combination of the starting value and the length as the index. The option-2 branch can be used as a starting point for this lesson.
Kyle explains how algorithms can be optimized by using memoization. When a path is followed, it can be saved using a combination of the starting value and the length as the index. The option-2 branch can be used as a starting point for this lesson.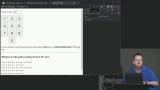 Kyle introduces dynamic programming, combining the memoization or top-down approach with the tabulation or bottom-up approach. This combination creates an algorithm that is both memory efficient and performant. The option-3 branch can be used as a starting point for this lesson
Kyle introduces dynamic programming, combining the memoization or top-down approach with the tabulation or bottom-up approach. This combination creates an algorithm that is both memory efficient and performant. The option-3 branch can be used as a starting point for this lesson Kyle visualizes how the dynamic programming approach will be applied to the counthPath function. Each iteration will tabulate the paths with a linear algorithmic complexity.
Kyle visualizes how the dynamic programming approach will be applied to the counthPath function. Each iteration will tabulate the paths with a linear algorithmic complexity.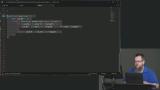 Kyle refactors the counthPaths function to use the bottom-up tabulation method of dynamic programming to determine how many paths are required for each hop. The final solution can be found on the option-4 branch.
Kyle refactors the counthPaths function to use the bottom-up tabulation method of dynamic programming to determine how many paths are required for each hop. The final solution can be found on the option-4 branch.
Wordy Problem
Section Duration: 2 hours, 6 minutes
 Kyle introduces the Wordy Scrambler problem and compares it to other word puzzles like Wordscapes where a scrambled list of letters must be decoded to make word combinations.
Kyle introduces the Wordy Scrambler problem and compares it to other word puzzles like Wordscapes where a scrambled list of letters must be decoded to make word combinations. Kyle talks through the possible algorithms which could be used to solve the Wordy Scrambler problem initially. Finding every permutation of the submitted word requires N-factorial executions. This will lead to performance issues with longer words.
Kyle talks through the possible algorithms which could be used to solve the Wordy Scrambler problem initially. Finding every permutation of the submitted word requires N-factorial executions. This will lead to performance issues with longer words. Kyle implements the initial solution to the Wordy Unscrambler problem. The algorithm uses a divide & conquer approach. Clone the repo linked below and checkout the start-here branch to begin the lesson.
Kyle implements the initial solution to the Wordy Unscrambler problem. The algorithm uses a divide & conquer approach. Clone the repo linked below and checkout the start-here branch to begin the lesson. Kyle walks through choosing a data structure and introduces the trie tree data structure. The loadWords function is implemented, which constructs the trie tree data structure. The option-1 branch can be used as a starting point for this lesson.
Kyle walks through choosing a data structure and introduces the trie tree data structure. The loadWords function is implemented, which constructs the trie tree data structure. The option-1 branch can be used as a starting point for this lesson. Kyle refactors the findWords function to utilize the trie tree data structure. If the current node in the tree is a word, the word is pushed into the words array. Otherwise, the function is recursively called with the remaining letters from the input.
Kyle refactors the findWords function to utilize the trie tree data structure. If the current node in the tree is a word, the word is pushed into the words array. Otherwise, the function is recursively called with the remaining letters from the input. Kyle introduces garbage collection and explains how object pooling reduces memory consumption by allocating the memory required to complete common operations and maintaining the pool size by recycling unused objects. The deepool library will be the object pool used in this application. The option-2 branch can be used as a starting point for this lesson.
Kyle introduces garbage collection and explains how object pooling reduces memory consumption by allocating the memory required to complete common operations and maintaining the pool size by recycling unused objects. The deepool library will be the object pool used in this application. The option-2 branch can be used as a starting point for this lesson. Kyle refactors the findWords function to implement the deepool library's object pool. A try/finally block is used because the finally part of the statement will execute even when an exception occurs. Since it executes every time, it's ideal for handling garbage collection. The option-3 branch can be used as a starting point for this lesson.
Kyle refactors the findWords function to implement the deepool library's object pool. A try/finally block is used because the finally part of the statement will execute even when an exception occurs. Since it executes every time, it's ideal for handling garbage collection. The option-3 branch can be used as a starting point for this lesson.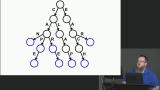 Kyle explains a radix tree is a trie tree that has been compacted. A radix tree would reduce the memory footprint in the application, however, the directed acyclic word graph structure is a better fit because it maintains a similar implementation while adding the memory optimizations.
Kyle explains a radix tree is a trie tree that has been compacted. A radix tree would reduce the memory footprint in the application, however, the directed acyclic word graph structure is a better fit because it maintains a similar implementation while adding the memory optimizations. Kyle implements the directed acyclic word graph. A third-party library is added to the project and the loadWords function is refactored. The option-4 branch can be used as a starting point for this lesson.
Kyle implements the directed acyclic word graph. A third-party library is added to the project and the loadWords function is refactored. The option-4 branch can be used as a starting point for this lesson.
Wrapping Up
Section Duration: 12 minutes
 Kyle wraps up the course by explaining an additional algorithm and sharing advice for approaching future algorithmic problems.
Kyle wraps up the course by explaining an additional algorithm and sharing advice for approaching future algorithmic problems.